Ruby ビギナーのための CGI 入門 【第 2 回】 ページ 1
はじめに
前号ではデータを表示する CGI プログラムを作りました。 HTML を表示させたり、ランダムに画像を表示させたりと CGI プログラムを使う事で Web ページに動きが出てきたのが感じられたと思います。
それはそれで面白いのですが、 どのプログラムもプログラム側が一方的にデータを 表示させていましたね。 皆さんが普段利用する CGI プログラムでは プログラムが一方的にデータを表示するのではなく、 Web ページの読者の投稿を受けたり、 読者のリクエストによって表示するデータが変わったりします。 要するに CGI プログラムと読者とやりとりがあるわけです。 自分でそういう CGI プログラムを作れれば もっと面白くなりそうですよね。
そこで、今号では読者からの投稿を受け取る CGI プログラムを作ってみましょう。 CGI プログラムで読者からの投稿を 受ける時には HTML フォームを使います。 HTML フォームと CGI プログラムを組み合わせることで CGI プログラミングの幅が広がり、 作れる CGI プログラムも増えてきます。
対象読者
この記事は以下のような人を対象としています。
- 前号 の記事を読んだ人
- HTML を書ける人
- Windows 98/98SE/Me/2000/XP のいずれかを使っている人
この連載は前号の記事を読んでいる人を対象として書かれています。 今号を読む前に前号の内容を把握しておいて下さい。
準備
必要なものはの下の 2 つです。
- サーバー
- Ruby
この他に RDE を使います。 これらの準備の方法は前号で述べたので、 詳しくはそちらを参照してください。 また、今号で使うプログラムを zip ファイルにまとめてあります。 前号と同じようにダウンロードし C:\ に展開して下さい。 rubima012-cgi.zip
今号で作る CGI プログラム
HTML フォームの使い方を知るには フォームを使った CGI プログラムを自分で書いてみるのが一番です。 今号ではフォームを使った CGI プログラムを 3 つ作ります。 3 つのプログラムを通じて HTML フォームの使い方に 馴れていきましょう。 3 つのプログラムは以下のようなものです。
- 「山彦もどき」
- 「山彦もどき改」
- 一行掲示板
1 つ目の「山彦もどき」というのはフォームに書かれた内容をそのまま 表示する CGI プログラムです。 フォームに書かれた内容をそのまま返すくらい 簡単と思われるかもしれませんが、 CGI プログラムではなかなか難しいのです。 ここでは CGI プログラムでフォームの内容を受け取る方法を学びます。 フォームデータを処理するために文字列を分割する方法も学びます。
2 つ目の「山彦もどき改」は「山彦もどき」の問題点を修正したものです。 ここでは「山彦もどき」を修正するために CGI プログラミングを支援する仕組みを使います。 この仕組みを使えば CGI プログラミングが楽になるので、 使い方を是非覚えてもらいたいと思います。 また、「山彦もどき改」には プログラムに ちょっとした仕掛けを 仕込んでみます。
3 つ目は一行掲示板です。ごくごく簡単な掲示板を 作成します。簡単なものとはいえ、立派な掲示板です。 ここでは掲示板のおおよその構造について学びます。 掲示板では投稿されたデータを保存したり表示したりするので、 ファイルの読み書きの方法についても学びます。
3 つとも前号よりかなり難しくなっていますが、 ここを乗り越えれば皆さんが一般に目にする CGI プログラムに近いものを作れるようになります。 是非チャレンジして下さい。
続 Ruby プログラムに馴れよう
今号も CGI プログラムの説明を行う前に Ruby の機能の説明を行います。 前号の知識では太刀打ち出来ない CGI プログラムが出てくるので、 まずはそうしたプログラムを作るための Ruby の知識を身に付けておきます。
プログラムが紹介された時には必ず自分で試してみて下さい。 RDE を使えば簡単に試せます。 Ruby に慣れるには、自分で試してみるのが一番です。
前号の復習
最初に前号の復習をしましょう。 前号では下のような Ruby の機能を使いました。
print, puts はデータを表示させる命令でしたね。 前号ではその print, puts を使って文字列や数値を表示させる CGI プログラムを作りました。 変数というのはデータへ目印を付けて、 後でそのデータが必要になった時に使いまわしが出来るという機能でした。 変数の文字列埋め込みや rand 命令は今号でも使います。 どんな機能だったか覚えていますか?
上の各項目はそれぞれの機能を説明したページへのリンクになっています。 もし、使い方に不安があるようでしたら、 リンク先の説明を読み直してみて下さい。
データの集まり - Array と Hash
ここではデータの集まりを扱う方法を紹介します。 そのためによく使われるのが Array や Hash です。 この 2 つは数値や文字列等と同じで Ruby のデータの一種なのですが、 大きく異なる点が 1 つあります。 それは 複数のデータをまとめて扱うことが出来る という点です。 言葉だけではなかなか把握しづらいでしょうから、 これから順に説明していきます。
Array や Hash が必要な場面はたくさんあります。 その 1 つが掲示板で多数のメッセージを処理する時です。 仮に表示したいメッセージが 100 個あったとして 100 個すべてを表示するにはどうしたら良いでしょうか? print を使えばそれぞれのメッセージを表示することは可能です。 しかし、そのやり方だと print “hogehoge” のような行を 100 回も 書くことになってしまい、とても面倒ですね。 そんな時に Array や Hash が役立ちます。
Array
Array がデータの集まりだというのは先程言ったとおりです。 でも、データの集め方には色々な方法がありますよね。 Array の場合は整理番号の付いた箱にデータが集められている と考えれば良いでしょう。
抽象的な話をしていても難しいだけなので、 実際に Array を使ったプログラムを書いてみましょう。
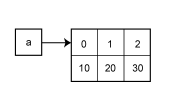
[10,20,30][10,20,30] というのが Array です。 [] で囲まれた部分が Array になり、 Array の中のデータは「,」で区切られます。 この場合は数値の 10 と 20 と 30 が 1 つの Array にまとめられています。
この Array を整理番号と一緒に図で表してみましょう。 下図のようになります。
| 0 | 1 | 2 |
| 10 | 20 | 30 |
上の段が整理番号で下の段が整理番号に対応するデータです。 整理番号の 0 には 10 が、整理番号の 1 には 20 が、 整理番号の 2 には 30 が対応することが分かりますね。
Array の整理番号は 0 から始まり、 中に含まれるデータが 1 つ増えると整理番号も 1 つ増えます。 そのため最後の整理番号はデータの個数より必ず 1 小さくなります。 例えば、Array に含まれるデータの個数が 10 個なら整理番号は 0 から9 までの範囲になりますし、 データの個数が 100 個なら 0 から 99 までの範囲になります。
整理番号の始まりが 1 でないと 嫌だという人もいるでしょうが、諦めて下さい。 そのうち馴れます。 馴れてくれば 0 から始まらない方が 気持ち悪いと感じるようになります (筆者もそのうちの一人です)。
ところで、今まで整理番号という言葉を使ってきましたが、 これは正しい用語ではありません。 Array では整理番号に相当する数値を 添字 と言います。 以後の説明では添字で統一するので、是非覚えて下さい。
Array の中のデータへのアクセス
Array の中のデータには [] と添字を使ってアクセスします。 下のようなプログラムを実行すると 添字の 0 に対応する 10 が表示されます。
a = [10,20,30]
puts a[0]Array はデータの一種ですから、 変数で目印を付けることが出来ます (変数がデータへの目印だということを覚えていますか?)。 変数 a の目印が付いているデータは [10,20,30] ですから、 2 行目の a[0] は [10,20,30] の添字 0 のデータ (つまり、10) を意味します。
上のプログラムの 1 行目を
前号のように図を使って表すと下のようになります。
少しは分かりやすいでしょうか?
今度は Array の中のデータを順番に表示させてみましょう。 上の例であれば Array の中には 3 個の数値が 入っているので、0, 1, 2 の添字を使って データにアクセスします。
a = [10,20,30]
puts a[0]
puts a[1]
puts a[2]今度はさっきと逆の順番で表示してみましょう。 簡単ですね。 先程のプログラムの 2 行目と 4 行目を入れ換えるだけです。
a = [10,20,30]
puts a[2]
puts a[1]
puts a[0]Array の中に含まれるデータは数値だけではありません。 また、違う種類のデータとの混在も可能です。 下の例では数値と文字列を混在させています。
a = ["url", 2005, 12, "rubima", "http://www.ruby-lang.org/"]
puts a[0]
puts a[1]
puts a[2]
puts a[3]
puts a[4]Array にデータを追加
これまで Array の中のデータにアクセスする方法を見てきました。 次は新しいデータを Array に追加してみましょう。 Array にデータを追加する時は 「<<」を使います。 Array の箱の中に「<<」でデータを押し込むというイメージを持てば 覚えやすいと思います。 実際に「<<」を使って Array にデータを追加にしてみましょう。
a = []
a << 3
a << 4
puts a[0]
puts a[1]上のプログラムは データの無い空の Array に 3, 4 を追加しています。 1 行目の [] は空の Array を表し、 その行で空の Array に変数 a の目印を付けています。 その後の 2, 3 行目では「<<」を使って それぞれ数値の 3, 4 を Array に追加しています。 その結果、空だった Array が 4 行目では [3,4] になります。
他の例も試してみましょう。 下のようにデータを追加する時にも違う種類のデータを混在出来ます。
a = ["るびま", "Ruby", 1]
a << "Rubima"
a << "CGI"
a << 2005Array の中のデータの個数を調べる - length
最後に Array の中のデータの個数を調べる方法を紹介しましょう。 Array のデータの個数が分からないと、 どの数値が添字として使えるのか分かりませんよね。
下の例であれば変数 a の目印が付いている Array (つまり、[10,20,30]) には 3 個のデータが含まれています。 この場合、3 という数値が欲しいわけです。
a = [10,20,30]結論から言えば [10,20,30] に length 命令を実行してもらうことでデータの個数を知ることが出来ます。 データに命令を実行してもらうというと ちょっと変な感じがするかもしれませんが、 Ruby のデータ (数値、文字列、Array、Hashなどなど) はデータ自身が実行出来る命令を持っています。 Ruby のデータは皆さんが考えているよりは ずっと賢いデータなんですね。 このことは今後重要な意味を持ってきます。 余裕のある人は覚えておきましょう。
a = [10,20,30]
puts a.length上のプログラムの「.」には データに命令を実行しろという意味があり、 実行して欲しい命令を「.」の後ろに書きます。 そのため上のプログラムを Ruby の立場から解釈すれば [10,20,30] に length を実行して欲しいという意味になります。 [10,20,30] は length という命令で何をするのか知っていて、 ちゃんと自分に含まれるデータの個数を教えてくれます。 この場合は 3 ですね。 これで添字に使える範囲が 0 から 2 までと分かります。
他の Array でも試してみましょう。 プログラムとその実行結果を下に示します。
puts [33, 22, 11].length
puts ["rubima", "cgi", "url", "html"].length
puts ["Ruby", "CGI", 2005, "http://jp.rubyist.net/magazine/", "number 2"].length3
4
5Array に含まれるデータの個数が表示されていますね。
Hash
Hash も Array と同じくデータの集まりです。 Hash と Array では細かい違いがいくつかありますが、 ここでは大きな違いを 1 つ説明します。 それは Hash では Array で言うところの添字に自分の好きなデータを使える という点です。実際の例を見てみましょう。
{"name" => "rubima", "number" => 12, "url" => "http://jp.rubyist.net/magazine/" }Ruby では {} で囲まれた部分が Hash になります。 「=>」の左と右のデータが組になっていて、 それぞれの組が Array と同じく「,」で区切られています。 「=>」の左側のデータが Array の添字に相当し、 右側のデータがその添字に対応するデータになります。 この Hash の場合なら下の 3 つの組が含まれていることになります。
- “name” には “rubima”
- “number” には 12
- “url” には “http://jp.rubyist.net/magazine/”
この Hash を図で表してみましょう。 上の段が Array で言うところの添字で 下の段がその添字に対応するデータです。 今回の例では添字に相当する部分が文字列 (“name”, “number”, “url”) になっていますから、 数値以外のデータも使えることが分かります。
| “name” | “number” | “url” |
| “rubima” | 12 | “http://jp.rubyist.net/magazine/” |
ここでまた言葉の説明をしておきましょう。 Array では図の上の段のデータのことを添字と言いましたが、 Hash の場合、上の段のデータのことをキー、下の段のデータのことをバリューと言います。 これも覚えて下さい。
Hash の中のデータへのアクセス
Hash の紹介が済んだところで そろそろ Hash を使ったプログラムを書いてみましょう。 最初は Hash に含まれるデータを表示させてみます。
a = {"name" => "rubima", "number" => 12, "url" => "http://jp.rubyist.net/magazine/" }
puts a["name"]
puts a["number"]
puts a["url"]順に rubima, 12, http://jp.rubyist.net/magazine/ と表示されますね。 上のプログラムを見れば分かると思いますが、 Hash の中のデータにアクセスするためには [] とキーを使います。 添字がキーに変わっただけでデータへのアクセス方法は Hash も Array も同じですね。
Hash にデータを追加
次に Hash に新しいデータを登録してみましょう。 下のプログラムは変数 a の目印の付いた Hash に データを追加しています。 1 行目で Hash を用意し、 2 行目で追加の処理が行われています。
a = {"name" => "rubima" }
a["number"] = 12[] を使ってキー (この場合は “number”) とバリュー (この場合は 12) の組を 「=」で登録します。 この結果、変数 a の目印の付いた Hash には 「”name” と “rubima”」「”number” と 12」という対応が含まれることになります。
もう 1 つ別の例を見てみましょう。 下のプログラムはデータの無い空の Hash にデータを登録していくプログラムです。 {} は空の Hash を表します。
a = {}
a["hoge"] = 3
a["bar"] = 2
a["baz"] = 1
a[3] = "hoge"
a[2] = "bar"
a[1] = "baz"1, 4, 7 行目が実行された後、 変数 a の Hash を図で表すと下のようになります。 Hash のキーにもバリューにも違う種類のデータを使用可能なことが分かりますね。 図ではなんとなく順番に並んでいるように見えますが、 それは筆者がそのように並べただけで、 実際の順番は滅茶苦茶です。
余裕のある人は print を使って Hash の中のデータを表示させてみて下さい。
1 行目
4 行目
| “hoge” | “bar” | “baz” |
| 3 | 2 | 1 |
7 行目
| “hoge” | “bar” | “baz” | 3 | 2 | 1 |
| 3 | 2 | 1 | “hoge” | “bar” | “baz” |
Array と Hash の each 命令
これまで Array と Hash を使って、 データをまとめる方法を見てきました。 Array や Hash にまとめられたデータを表示したり、 データを追加したり出来るようになったと思います。 でも、こうした処理だけでは 100 個のメッセージを扱うのは大変そうです。
そういう時のために Array や Hash には専用の命令があり、 その命令を使う事でたくさんのデータを扱うのが楽になります。 それらの命令の中で最もよく使われるのが each 命令です。 each 命令の使い方は難しいので、 ここでは紹介だけにとどめますが、 Array や Hash を使ってデータをまとめることの意味が実感できると思います。
下のプログラムは Array の中のデータをすべて表示させます。 Array に each 命令を実行してもらうことで 何回も print や puts を書かないで済ませることが出来ます。
[10,12,13,15,3,34,"abc",12,87,23,"dddd",456,7345].each do |i|
puts i
end次は Hash です。 次のプログラムは Hash の中に含まれるキーとバリューを表示させます。 こちらも Hash に each 命令を実行してもらうことで Hash の中のキーとバリューをすべて表示させます。
{1=>2, "aaa"=>"AAAA", "rubima" => "http://jp.rubyist.net/magazine/"}.each do |k, v|
puts k
puts v
endeach の詳しい使い方はこの連載で後ほど説明します。 Ruby の特徴の 1 つが each に見られるのですが、 その説明は皆さんにはまだ少し難しいと思います。 each は後の楽しみとしてとっておきましょう。
環境変数 - ENV
次に紹介するのは環境変数というデータです。 フォームを使った CGI プログラムでは環境変数が頻繁に使用されるのですが、 その説明はまた後ですることにして、 ここでは環境変数のことだけを紹介します。 一言でいうと __環境変数というのは OS やプログラムを動かすためのデータが格納されているところ__です。
環境変数を見てみる
まずは皆さんがお使いの Windows にどんな環境変数が あるのか見てみましょう。 Windows では環境変数はあまり利用されないので、 ほとんどの方は環境変数なんて使ったことも見たことも無いと思います。 筆者も Windows だけを使っている間は 環境変数なんて存在すら知りませんでした。
環境変数を見る方法は Windows のバージョンによって違います。
Windows 2000/XP であれば スタートメニュー → コントロールパネル → システム
とたどっていって、システムのプロパティのダイアログを表示させます。
XP でコントロールパネルのカテゴリ表示をしている人は
スタートメニュー → コントロールパネル → パフォーマンスとメンテナンス → システム
とたどらなければなりません。
下図は XP でパフォーマンスとメンテナンスの画面を出したところです。
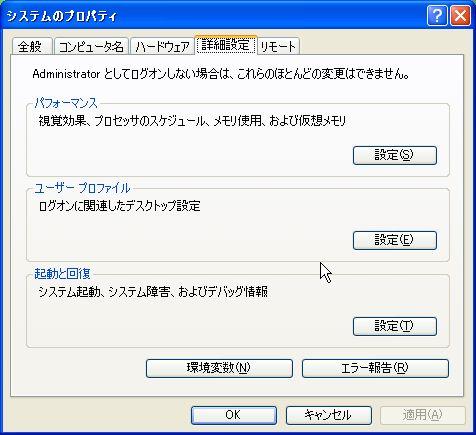
システムのプロパティのダイアログが出てきたら 詳細設定タブ (Windows 2000では詳細タブ) をクリックし、 その中の環境変数ボタンをクリックします。 XP と 2000では環境変数のボタンの位置が違うので、 注意してください。
Windows XP
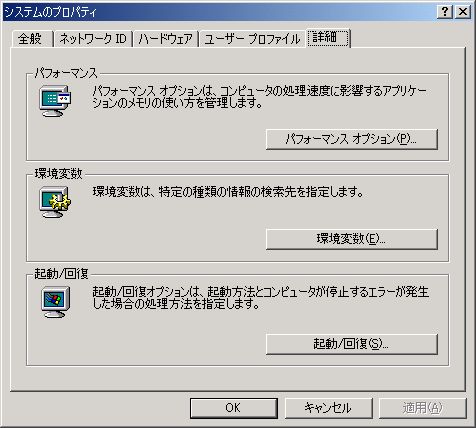
Windows 2000
環境変数ボタンを押すと、
現在使われている環境変数の一覧が出てきます。
システム環境変数とユーザー環境変数の 2 つに分かれていますが、
それは無視してもらって結構です。
下の図は Windows 2000 の場合です。
編集や削除のボタンがありますが、この 2 つには無闇に触らないようにしましょう。
最悪の場合、Windows が動かなくなるかもしれません
(怖いので筆者は試していません…)。
「変数」や「値」という項目があって、その下に文字が並んでいます。 例えば、ユーザー環境変数の「変数」には PATH や TMP といった項目があり、 その横には「値」が表示されています (図ではデータを塗りつぶしています)。
これらは組を作っています。その説明はのちほど行います。 とりあえずこんな値があるんだということだけ理解して下さい。
環境変数の使い方
環境変数の使い方は OS やプログラムが決める事なので、 その使用方法は多岐にわたります。 そのため環境変数の使い方をこうだと決め付けることが出来ません。 代わりにここでは環境変数の使用例を 2 つほど紹介しましょう。
1 つ目は Ruby の翻訳機です (意外かもしれませんが、Ruby の翻訳機もプログラムの 1 つです)。 One-Click Ruby Installer で Ruby をインストールした方の Windows には、 システム環境変数のところに RUBYOPT という項目があるはずです。 これは Ruby プログラムが実行される時に Ruby が参照する環境変数の 1 つです。 Ruby プログラムが実行される時、Ruby は RUBYOPT で 指定された名前のファイルを読み込みにいきます。 (Ruby がファイルを読み込んだらどうなるとか、 詳細は今は分からなくても構いません。 環境変数にこんな使い方があるんだということを掴んで下さい)。
もう 1 つの例は環境変数 TMP です。 OS や各種プログラムは環境変数の TMP の「値」のフォルダーに 一時的なファイルを置きます。
下図は環境変数 TMP に
C:\Documents and Settings\administrator\Local Settings\Temp
が指定されている時のフォルダーの内容です。
C:\Documents and Settings\administrator\Local Settings\Temp
のフォルダーが一時ファイル置き場として使われていて、
色々なファイルがあります。
環境変数 ENV の中のデータを見てみる
Ruby のプログラムからも環境変数のデータを使えます。 その時には ENV を使います。 ENV は変数のようなもので、あるデータへの目印になっています。 何のデータに目印が付いているのかというと、それは環境変数そのものです。
まずは環境変数 ENV について詳しく見てみましょう。 環境変数 ENV には「名前」とその「名前」に対応する「値」が組になって含まれています。 例えば、RUBYOPT の場合は「RUBYOPT」という「名前」に 「rubygems rubygems」という「値」が組になります。 この関係は Hash のキーとバリューに似ていて、 環境変数の「名前」が Hash のキーに、「値」がバリューに対応します。 環境変数にはこうした「名前」と「値」の組がたくさん含まれています。
先程の RUBYOPT や TMP を例に取れば、 下のような組が ENV に含まれると考えられます。 「C:\Documents …」 の「\」が「/」に変わっていますが、それは気にしないで下さい。
- “RUBYOPT” と “rubygems rubygems “
- “TMP” と “C:/Documents and Settings/administrator/Local Settings/Temp”
図にすると下のようになります。 イメージとして ENV は Hash に似ていますね。
| “RUBYOPT” | “TMP” |
| “rubygems rubygems “ | “C:/Documents and Settings/administrator/Local Settings/Temp” |
先程表示させた環境変数ダイアログでは 環境変数が「変数」と「値」の組として表示されていますが、 それだと Ruby の変数と紛らわしいので、 この連載では環境変数の説明の際に「変数」の代わりに「名前」を使うことにします。
次に環境変数のデータを Ruby プログラムから表示させてみます。 下のプログラムは環境変数の RUBYOPT の「名前」に対応する「値」を表示させます (実際に表示される値は “rubygems rubygems “ です)。 RDE で試してみて下さい。
puts ENV["RUBYOPT"]Ruby から ENV を使う時も「名前」と [] を使って「値」にアクセスします。 データへのアクセス方法も環境変数と Hash はよく似ていますね。 環境変数には文字列が格納されていて、 ENV から取り出した「値」には文字列をつなげたり出来ます。 試しに RUBYOPT の「値」に “rubyruby” をつなげてみましょう。
a = ENV["RUBYOPT"] + "rubyruby"
puts a他の環境変数も表示させてみます。 下のプログラムはそれぞれ TMP, PATH, OS に 対応する環境変数の「値」を表示します。 環境変数ダイアログで見た「値」と一致しているかどうか確認してみて下さい。
puts ENV["TMP"]
puts ENV["PATH"]
puts ENV["OS"]ここでは環境変数の説明を行いました。 最初に言ったように環境変数は フォームを使った CGI プログラムで必要になります。 CGI プログラムを作る時に「ENV って何?」とならないように ENV のデータへのアクセス方法を覚えておいて下さい。
if 文
Ruby の勉強でもうお腹いっぱいという人は ここを飛ばしてもらって結構です。 ただし、後で必要になるので、その時にはここに戻ってきて読み直して下さい。
データの値によって処理を変えたいというのはよくある事です。 現在の時刻によって挨拶の言葉を変えたり、 投稿内容のタグを消したり、という CGI プログラムは Web サイトを回れば時々見かけます。
こういう時に必要となるのが if 文です。 if 文を使うと指定した条件に合わせて処理の内容を 変化させることが出来ます。
処理の流れを分岐させる
試しに if 文を使ってみましょう。 下のプログラムを実行すると、「a」 は表示されますが、 「b」 は表示されません。
a = 1
if a == 1
print "a"
else
print "b"
endこれは if 文によって処理の流れが分岐したからです。 通常、Ruby のプログラムは上から順番に実行されますが、 if 文を使うことで処理の流れを分岐させる事が出来ます。
プログラムの内容はすぐ後で説明するので、
まずは処理の流れを追ってみましょう。
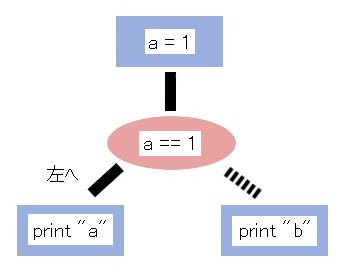
上のプログラムを図で示してみました。
図の上から順番に処理が実行されていきます。
最初は 1 行目の a = 1 が実行され、
次の 2 行目の if 文が実行されます。
この図では 2 行目が赤丸で表されていて、
ここで処理が分岐します。
今回の場合は左側へ処理の流れが進んで 3 行目が実行されて、
「a」が表示されます。
右側は無視されるので、「b」は表示されません。
このように処理を分岐させたい時に if 文を使います。
if 文の使い方
if 文の使い方は
if (条件)
(処理の内容 1)
endもしくは
if (条件)
(処理の内容 1)
else
(処理の内容 2)
endとします。
(条件) を満たしている時に (処理の内容 1) が実行されます。 else の付いた形では (条件) を満たしていない時、 (処理の内容 1) の代わりに (処理の内容 2) が実行されます。 (条件) を満たさない時に処理することが無ければ else とそれに続く処理の内容を省くことが出来ます。
上のプログラムの場合、条件というのは赤丸の a == 1 です。 これは「変数 a の目印の付いたデータが 1 と等しいならば」という意味です。 「==」は Ruby では等しいという意味があります。 上のプログラムでは変数 a は 1 への目印ですので、 if 文の条件を満たすことになり、 (処理の内容 1) にあたる 3 行目の print “a” が実行されます。
試しに a = 1 の行を a = 2 に変えて実行してみて下さい。 今度は b が表示されますね。 変数 a が 2 への目印になると a == 1 が正しくなくなり、 if 文の条件を満たさなくなって (処理の内容 2) の 5 行目が実行されます。
if 文は CGI プログラムの色々な場面で活躍します。 例えば、if 文を使ってフォームのデータが 何らかの条件と合致するかを調べれば、 フォームのデータに合わせて処理を分岐させることが可能になります。