Ragel 入門: 簡単な使い方から JSON パーサまで
著者: 桑田 誠
はじめに
Ragel とは、Adrian Thurston によって作られたステートマシンコンパイラです。 Ragel を使うと、コンパイラやパーサの字句解析部を簡単に作れます。 また Ragel は複数の言語に対応しており、現在のところ C/C++/Objective-C/D/Java/Ruby のソースコードを生成することができます。
ステートマシン (状態機械) とは、簡単にいえば状態遷移図のことです。 ステートマシンは入力をひとつずつ読み込むたびに状態を遷移します。 そして入力が終了した時点でどの状態に遷移しているかを調べることで、入力が正しいかどうか等を知ることができます。
ステートマシンの使い道は様々です。
- コンパイラの字句解析として使う。
- データが正しい形式かどうかを確かめるために使う。
- 正規表現の代わりとして使う。
- Web アプリケーションの画面遷移を設計するのに使う。
実際に Ragel を使っているプロダクトとしては以下のものがあります (Ragel のページより抜粋)。
本稿では、Ruby における Ragel の基本的な使い方を説明し、そのあと応用例として JSON パーサを作成してみます。
なお本稿を読む上で、構文解析や字句解析の知識はあったほうが望ましいですが、必須ではありません。 少なくとも試してみるだけなら誰にでもできますので、構文解析や字句解析を知らなくても問題はありません。
また Ragel についての詳細は、Ragel User Guide をご覧下さい。
インストール
Ragel は Rabel の Web サイト からダウンロードできます。 Windows 用のバイナリも用意されています。 ソースからコンパイルする場合は次の手順で行ってください。
$ wget http://www.cs.queensu.ca/~thurston/ragel/ragel-6.0.tar.gz
$ tar xzf ragel-6.0.tar.gz
$ cd ragel-6.0/
$ ./configure --prefix=/usr/local
$ make
$ sudo make install
$ which ragel
/usr/local/bin/ragel
$ ragel -v
Ragel State Machine Compiler version 6.0 January 2008
Copyright (c) 2001-2007 by Adrian Thurstonまた必須ではありませんが、状態遷移を可視化するために、Graphviz をインストールすることをお勧めします。
Graphviz をインストールするには、http://www.graphviz.org/Download.php にアクセスし、一番下の「Agree」をクリックします。 するとダウンロードページになるので、そこから OS 別のバイナリをダウンロードしてください (依存するライブラリが多いので、自力でコンパイルするのはお勧めしません)。 MacOS X で MacPorts を使っている場合は、「sudo port install graphiz」でインストールできます。
$ sudo port install graphviz基礎編: Ragel の使い方
Ragel はステートマシンコンパイラです。 Ragel の使い方を知るために、まずは簡単なサンプルを作ってみましょう。
状態遷移図を生成する
ステートマシンを説明するために、まずは Ragel の文法定義から状態遷移図を生成してみます。
list-1 をご覧下さい。これは整数と小数を認識するためのサンプルです。
list-1. ex1.rl: 整数と小数を認識する文法
{{*%%{*}}
## ステートマシンの名前
{{*machine ex1;*}}
## 文法定義
{{*main := ('+' | '-')? [0-9]+ ('.' [0-9]+)? ;*}}
{{*}%%*}}ポイントは次の通りです。
- 1, 9行目: Ragel のステートマシン定義は、「%%{」から「}%%」までの間に書きます。または 1 行だけなら「%%」で始まる行に書くこともできます。
- Ragel では、ステートマシンに名前をつける必要があります。この名前は、Ruby や C のコードを生成した場合の、変数名の接頭辞になります。
- 7行目: 「main :=」から「;」までが文法定義になります1。ここに、文法のパターンを書きます。
-
「(‘+’ ’-‘)?」は、符号があってもなくてもいいことを表します。 - 「[0-9]+」は、数字が 1 回以上繰り返されることを表します。
- 「(‘.’ [0-9]+)?」は、ピリオドのあとに数字が 1 回以上繰り返されることを表します。また「?」があるので、全体が省略可能であることがわかります。
- 「#」で始まる行はコメントです。
-
文法を見てみると、正規表現によく似ていることがわかります。 実際、Ragel の文法で書けるのは正規言語といい、表現能力は正規表現と (概念的には) 同じです (ただし Ruby の正規表現は本来の正規表現と比べて拡張されているので、Ragel とまったく同じというわけではありません)。
これをコンパイルして、状態遷移図の画像ファイルに変換してみましょう (list-2)。
list-2. ステートマシンのコンパイルと表示
### Ragel でコンパイル
$ ragel -Vp ex1.rl > ex1.dot
### Graphviz で画像ファイルに変換
$ dot -Tpng ex1.dot > ex1.pngこれを実行すると、fig-1 のような画像が生成されます。 以下はその説明です。
- 「○」と「◎」は状態を表します。「◎」は受理状態といい、入力が終了した時点でその状態になっていれば入力が文法にマッチした (== 入力が受理された) ことを表します。
- 矢印は状態遷移を表します。矢印についてる文字は、その遷移が起こる入力を表します。
fig-1. ex.rl から作成された状態遷移図
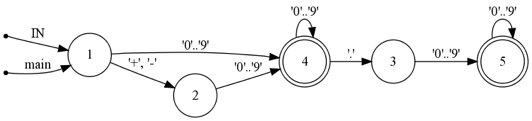
この図から、次のことがわかります。
- 状態数は全部で 5 つ
- 初期状態は 1
- 受理状態は 4 と 5
このように、Ragel を使うと状態遷移図が簡単に作成できます。
なお Ragel では、受理状態につけられる番号は、そうでない状態につけられる番号よりも大きくなります。 fig-1 で状態の番号が左から「1 2 3 4 5」ではなく「1 2 4 3 5」となっているのはこれが理由です。 このおかげで、ある状態番号 N が与えられたとき、それが受理状態かどうかを簡単に判定できます。 例えば fig-1 では N >= 4 なら受理状態であることが分かります。
また図には現れていませんが、Ragel ではエラーがあった場合に遷移する状態 0 が用意されています。
パターンに別名をつける
Ragel では、パターンに別名をつけることができます。
list-3 をご覧下さい。 先ほどの定義ファイルに加え、符号を表す「sign」と、数値を表す「d」の、2 つの別名を定義しました2。 また文法の定義も、別名を使うように変更しています。
list-3. ex2.rl: パターンに別名を追加
%%{
## ステートマシンの名前
machine ex2;
{{*## 別名の定義*}}
{{*sign = '+' | '-';*}}
{{*d = [0-9];*}}
## 文法定義
main := {{*sign*}}? d+ ('.' {{*d*}}+)? ;
}%%この定義ファイルを使って状態遷移図を生成すると、fig-1 とまったく同じものが得られます。
なお Ragel では、以下のような別名があらかじめ定義されてあります。 詳しくは Ragel User Guide, Section 2.3 Basic Machines をご覧下さい。
- any
- 任意の文字
- ascii
- アスキー文字。文字コードだと 0 から 127 まで。
- alpha
- アルファベット。「[A-Za-z]」と同じ。
- digit
- 数字。「[0-9]」と同じ。
- alnum
- アルファベットまたは数字。「[0-9A-Za-z]」と同じ。
- xdigit
- 16進数で使う文字。「0-9A-Fa-f」と同じ。
- space
- 空白文字。「[\t\v\f\n\r ]」と同じ。
Ruby コードを生成する
実際に状態遷移を行うコードは、Ragel が自動生成してくれます。 そのためには、ソースコードに以下を記述します。
- %% write data;
- ステートマシンに必要なデータを生成します。
- %% write init;
- ステートマシンに必要な変数を初期化します。
- %% write exec;
- ステートマシンを実行します。
また、パターンに一致したときに任意の Ruby コードを実行させることができます。 これをアクションといいます。 アクションには名前を付けることができ、文法定義において実行したいアクション名をパターンの中に埋め込みます。
実際のコードは list-4 のようになります。 このコードでは、ステートマシンを実行するのに必要なコードもすべて書いてあります。 ここでのポイントは次の通りです。
- 12, 19, 24行目
- 符号、整数部、小数部のそれぞれにマッチしたときのアクションを定義しています。
- 32行目
- 文法定義のパターンの中に、アクション名を指定しています。
- 40行目
- Ragel によって、ステートマシンに必要なデータを生成する Ruby コードに変換されます。
- 47行目
- 入力文字列をバイトの配列に変換します。Ragel では「data」という名前の配列に格納されたバイトを 1 つずつ読み込んで、状態遷移を実行します。
- 60行目
- Ragel によって、ステートマシンに必要な変数を初期化するコードに変換されます。この場合なら、「p」(現在位置を表す)、「pe」(終了位置を表す)、「cs」(現在の状態番号を表す) というローカル変数が初期化されます。
- 63行目
- Ragel によって、状態遷移を実行する Ruby コードに変換されます。
- 69行目
- 受理状態かどうかを調べます。「cs」は現在の状態を表す番号が入った変数で、「ext3_first_final()」は受理状態のうち最も小さい番号を返すメソッドです。受理状態であれば、cs >= ext3_first_final() が true となるはずです。
list-4. ex3.rl: アクション定義
%%{
## ステートマシンの名前
machine ex3;
## 別名の定義
sign = '+' | '-';
#d = [0-9];
## アクションの定義
## (アクションとは、パターンにマッチしたとき実行される処理のこと)
{{*action on_sign {*}}
## 「fc」は現在読み込んでいる文字のことであり、
## Ragel によって「data[p]」に展開される。
## (「data」と「p」については後述)
sign_char = {{*fc*}}
puts "*** on_sign: sign_char=#{sign_char.inspect}" if $DEBUG
{{*}*}}
{{*action on_int {*}} # 整数部のアクション
ch = {{*fc*}}
puts "*** on_integer: ch=#{ch.inspect}" if $DEBUG
val = val * 10 + (ch - ?0)
{{*}*}}
{{*action on_float {*}} # 小数部のアクション
ch = {{*fc*}}
puts "*** on_float: ch=#{ch.inspect}" if $DEBUG
e = 0.1 * e
val += e * (ch - ?0)
{{*}*}}
## 文法定義において、アクション名を指定する。
main := sign? {{*@on_sign*}} digit+ {{*@on_int*}} ('.' digit+)? {{*@on_float*}} ;
}%%
class Ex3Scanner
def initialize
## ステートマシンに必要なデータを生成する
{{*%% write data;*}}
end
def scan(input)
## 入力文字列をバイトの配列に変換する。
## (Ragel では 1 バイトずつ読んで状態遷移するため。)
## なお「data」という変数名は Ragel により決めうち。
{{*data = input.unpack('c*')*}}
## アクションで使う変数
sign_char = nil
val = 0
e = 1.0
## ステートマシンを初期化する
## (Ragel により
## p ||= 0 # 現在位置 (pointer)
## pe ||= data.length # 終了位置 (end pointer)
## cs = ex3_start # 現在の状態 (current state)
## に展開される)
{{*%% write init;*}}
## ステートマシンの実行
{{*%% write exec;*}}
## エラーチェック
## (cs は現在の状態を表す番号、
## ext3_first_final() は受理状態を表す番号のうち
## 最も小さいもの (今回なら 4) を返す。)
unless {{*cs >= ex3_first_final*}} # 受理状態でなければエラー
raise "** syntax error (p=#{p}, data[p]='#{data[p].chr}')"
end
## 解析した値を返す
return sign_char == ?- ? -val : val
end
end
if $0 == __FILE__
scanner = Ex3Scanner.new
while line = gets()
line.chomp!
val = scanner.scan(line)
puts "val=#{val.inspect}"
puts "OK."
end
end実際に動作させるには、Ragel を使ってこのコードをコンパイルし、Ruby のソースコードを生成します(list-5)。
list-5. コンパイルと実行
$ ragel -R ex3.rl # ex3.rl から ex3.rb を生成
$ ruby ex3.rb
-123
val=-123
OK.
3.14
val=3.14
OK.
123daa!
ex3.rb:277:in `scan': ** syntax error (p=3, data[p]='d') (RuntimeError)
from ex3.rb:290なお Ragel には、アクションのより高度な指定方法や細かい変数が存在します。 詳しくは Ragel User Guide, Chapter 3 User Actions をご覧下さい。
字句解析 (Scanner) を作成する
ステートマシンは、コンパイラを作成する際の字句解析 (Scanner) によく使われます。 そのため、Ragel ではわざわざ字句解析用の機能を用意しています。
Ragel のこの機能を使うには、文法定義において「|」と「|」を使い、その中にトークンのパターンとアクションを記述します。 具体的には list-6 のような書き方になります。
list-6. Ragel における字句解析部の書き方
%%{
main := |*
{{/pattern1/}} { {{/action1/}} };
{{/pattern2/}} { {{/action2/}} };
{{/pattern3/}} { {{/action3/}} };
*|;
}%%またステートマシンを初期化する「%% write init;」においても、次のように初期化する変数が増えます。
- ts
- トークンの開始位置を表す変数。
- te
- トークンの終了位置を表す変数。
- act
- 直前に成功したパターンを表す変数。バックトラックで使用される。
実際の例は list-7 をご覧下さい。 この例ではトークンとして整数と小数と識別子を認識します。 また空白文字は、アクションに何も記述しないことで読み飛ばしています。
list-7. ex4.rl: 字句解析
%%{
## ステートマシンの名前
machine ex4;
## 別名の定義
sign = '+' | '-';
## 文法定義
main := {{*|**}}
## 空白
{{*space+ {*}}
## 読み飛ばす
{{*};*}}
## 整数
{{*sign? digit+ {*}}
{{*token = :INT*}}
{{*fbreak;*}} # 状態遷移のループを抜ける
{{*};*}}
## 小数
{{*sign? digit+ '.' digit+ => {*}}
{{*token = :FLOAT*}}
{{*fbreak;*}} # 状態遷移のループを抜ける
{{*};*}}
## 識別子
{{*[a-zA-Z_] [a-zA-Z0-9_]* {*}}
{{*token = :IDENT*}}
{{*fbreak;*}} # 状態遷移のループを抜ける
{{*};*}}
{{**|;*}}
}%%
class Ex4Scanner
def initialize
## ステートマシンのデータ
%% write data;
end
def scan_all(input)
## 入力文字列をバイトの配列に変換する。
## なお「data」という変数名は Ragel により決めうち。
data = input.unpack('c*')
## ステートマシンの初期化
## (Ragel により
## p ||= 0 # 現在位置 (pointer)
## pe ||= data.length # 終了位置 (end pointer)
## cs = ex4_start # 現在の状態 (current state)
## ts = nil # トークン開始位置 (token start)
## te = nil # トークン終了位置 (token end)
## act = 0 # バックトラックで使う変数
## に展開される)
%% write init;
## 変数 eof を設定する (必須)
{{*eof = data.length*}} # eof = pe でもよい
## メインループ
while true
token = nil
## ステートマシンの実行
%% write exec;
## エラーチェック
unless cs >= ex4_first_final
s = data[p].chr
raise "** syntax error (cs=#{cs}, p=#{p}, data[p]='#{s}')"
end
## 入力の終わりならループを抜ける
break unless token
## トークンを表示する
## (ts と te はトークンの開始位置と終了位置を表す)
token_str = {{*input[ts...te]*}}
puts "** token=#{token.inspect}, str=#{token_str.inspect}"
end
end
end
if $0 == __FILE__
scanner = Ex4Scanner.new
while line = gets()
scanner.scan_all(line)
puts "OK."
end
endこれを Ragel でコンパイルして実行してみましょう。 整数や小数や識別子がトークンとして認識されること、空白が読み飛ばされること、記号があるとエラーとなることが確認できます (list-8)。
list-8. コンパイルと実行
$ ragel -R ex4.rl # ex4.rl をコンパイルして ex4.rb を生成
$ ruby ex4.rb
123 -3.14 foo
** token=:INT, str="123"
** token=:FLOAT, str="-3.14"
** token=:IDENT, str="foo"
OK.
func(123)
** token=:IDENT, str="func"
ex4.rb:418:in `scan_all': ** syntax error (cs=0, p=4, data[p]='(') (RuntimeError)
from ex4.rb:438Ragel の字句解析機能についての詳細は、Ragel User Guide, Section 6.3 Scanners を参照して下さい。
応用編: JSON パーサ
具体的な応用例として、Ragel を使ってJSONパーサを作ってみましょう。
ちょっと小難しい話をすると、JSON の仕様は文脈自由文法を使って定義されるため、正規言語を使う Ragel では JSON パーサを記述できません3。 そのため、今回は JSON パーサ自体は再帰下降法を使って手書きし、字句解析部分を Ragel で作成します。
ただし、今回はあくまで Ragel の使い方を紹介するのが目的なので、JSON の仕様に忠実に従ったパーサではなく、都合の良いところで改変しています。 その点はご注意ください。
字句解析部 (Scanner)
字句解析部は、次のような仕様にしました。 一部、JSON の仕様と合わない点がありますが、サンプルですので目を瞑ってください。
- 次のものを読み飛ばす。
- 空白、改行、タブ文字
- 行コメント (//…)
- 範囲コメント (/* … */)
- 次のものをトークンとして認識する (カッコ内はトークン記号)。
- 10進数整数 (:DECIMAL)
- 16進数整数 (:HEXADEC)
- 小数 (:FLOAT)
- 識別子 (:IDENT)
- 文字列 (:STRING)
- 予約語 (:TRUE, :FALSE, :NULL)
- 記号 (?{, ?}, ?[, ?], ?:, ?,)
- これら以外の記号があればエラー。
- 文字列中の “\n” や “\uXXX” はエンコードしない。
- 「3.0e5」のような表記はサポートしない。
実際のコードは list-9 の通りです。 ここでのポイントは次の通りです。
- 6, 9行目: ステートマシンの状態を、ローカル変数ではなくインスタンス変数に格納するようにする。これはトークンを返すメソッド (JsonScanner#scan()) をパーサから呼び出せるようにするため。
- ステートマシンの初期化は JsonScanner オブジェクト作成時に行う。トークンを返すメソッド (JsonScanner#scan()) の中で行ってはならない。
- 25行目: 行コメントを表すパターンは「’//’ [^\n]* ‘\n’」である。
- 29行目: 範囲コメントを表すパターンは「’/’ any :>> ‘*/’」である。ここで「any」は任意の文字を表す。また「:>>」はその直後のパターンにより高い優先順位を与える演算子 (詳しくは Ragel User Guide, Section 4.2.2 Finish-Guarded Concatenation を参照)。
-
72行目: 文字列を表すパターンは「’”’ ( [^”\] ( ‘\’ any ) ) ‘”‘」となる。ただしこのままだと見にくいので、実際のコードでは別名を使って 2 つに分割している。
また字句解析部で発生するエラーは、次の通りです。
- 141行目: 不正な文字が見つかったとき。
- 148行目: 「”」で始まった文字列が閉じずに EOF になったとき。
- 150行目: 「/*」で始まった範囲コメントが閉じずに EOF になったとき。
- 152行目: 「//」で始まった行コメントが改行で終わらずに EOF になったとき。
このうち、4 番目はエラーにしなくても構わないので、例外を投げないようにしています。
list-9. json_scanner.rb: 字句解析部
%%{
## ステートマシンの名前 (接頭辞)
machine json;
## 変数 cs の頭に「@」をつける
access @;
## 変数 p, pe, eof も同様
variable p @p;
variable pe @pe;
variable eof @eof;
## 別名の定義
sign = ('+' | '-');
## 文法定義
main := |*
## 空白類を読み飛ばす
space+ { # (「space」は「[ \t\v\f\n\r]」の別名)
};
## '//' から改行まで読み飛ばす (行コメント)
'//' [^\n]* '\n' {
};
## '/*' から '*/' まで読み飛ばす (範囲コメント)
'/*' any* :>> '*/' { # 「any」は任意の文字を表す
};
## 小数 (float)
sign? [0-9]+ '.' [0-9]+ {
@token = :FLOAT;
fbreak;
};
## 10進数 (decimal)
sign? [0-9]+ {
@token = :DECIMAL;
fbreak;
};
## 16進数 (hexadecimal)
sign? '0x' [0-9a-fA-F]+ {
@token = :HEXADEC;
fbreak;
};
## 予約語 (keyword)
## (末尾の i は大文字小文字を区別しないことを表す)
'true'i {
@token = :TRUE;
fbreak;
};
'false'i {
@token = :FALSE;
fbreak;
};
'null'i {
@token = :NULL;
fbreak;
};
## 識別子 (identifier)
[a-zA-Z_] [a-zA-Z0-9_]* {
@token = :IDENT;
fbreak;
};
## 文字列 (string)
dqchar = [^"\\] | ( '\\' any ); #"
'"' . dqchar* . '"' {
@token = :STRING;
## 先頭と末尾の '"' を取り除く
## ("\n" や "\uXXX" のデコード処理は省略)
@token_str = @input[(@ts+1)...(@te-1)]
fbreak;
};
## 記号 (symbol)
[\{\}\[\]:,] {
@token = fc;
fbreak;
};
*|;
}%%
##
## 字句解析クラス
##
## 使い方:
## scanner = JsonScanner.new(File.read('file.json'))
## while token = scanner.scan()
## token_str = scanner.token_str
## puts "** token=#{token.inspect}, str=#{token_str.inspect}
## end
##
class JsonScanner
def initialize(input=nil)
## ステートマシンのデータを生成
%% write data;
## 文字列があればそれを使って初期化
setup(input) if input
end
def setup(input)
@input = input
## 入力文字列をバイトの配列に変換
@data = input ? input.unpack('c*') : []
## ステートマシンに必要な変数を初期化
%% write init;
#@p ||= 0;
#@pe ||= @data.length;
#@cs = json_start
#@ts = nil
#@te = nil
#@act = 0
@eof = @pe;
end
attr_reader :cs, :p, :pe, :eof, :ts, :te, :act
attr_reader :input, :token, :token_str
def scan
@token = @token_str = nil
## ステートマシンを実行
%% write exec;
## エラーチェック
handle_error() unless @cs >= self.json_first_final
## トークンの文字列を設定する
@token_str = @input[@ts...@te] if !@token_str && @token
## トークンを返す
return @token
end
def handle_error
if @cs == self.json_error ## 不正な文字があった場合
ch = @data[@p]
s = [ch].pack('c')
_raise "#{s.dump}: invalid character."
else
s = @input[@ts..-1]
case s
when /\A"/ ## 文字列が閉じるまえに EOF になった場合
_raise "string literal is not closed by '\"'."
when /\A\/\*/ ## 範囲コメントが閉じずに EOF になった場合
_raise "region comment is not closed by '*/'."
when /\A\/\// ## 行コメントが改行で終わらずに EOF になった場合
## これはエラーにしなくてよい
end
end
end
private :handle_error
def _raise(mesg)
linenum, column = get_position()
err = StandardError.new("#{linenum}:#{column}: #{mesg}")
err.set_backtrace(caller())
raise err
end
private :_raise
def get_position(index=nil)
index ||= @ts
s = @input[0..index]
linenum = s.count("\n") + 1
column = s.length - (s.rindex("\n") || -1) - 1
return linenum, column
end
end
## 字句解析クラスの使い方
if __FILE__ == $0
input = ARGF.read()
scanner = JsonScanner.new(input)
while token = scanner.scan()
token_str = scanner.token_str
puts "** token='#{token.chr}', token_str=#{token_str.dump}"
end
end構文解析部 (Parser)
構文解析部 (Parser) では Ragel は使わず、再帰下降法を使って手書きしています。 JSON 程度であれば、これがいちばん簡単で分かりやすいでしょう。
ここでのポイントは次の通りです。
- 36行目: parse_object() はオブジェクト ({…}) を構文解析するメソッドです。トークンが ?{ のときに呼び出されます。
- 71行目: parse_array() は配列 ([…]) を構文解析するメソッドです。トークンが ?[ のときに呼び出されます。
- 95行目: parse_value() は任意の値を解析するメソッドです。トークンの値を調べ、適切な値を返します。
- 49, 52, 106行目: オブジェクトのキーに識別子がある場合は、文字列と同じように扱います。それ以外の場所に識別子があると、エラーになります。
list-10. json_parser.rb: 構文解析部 (Parser)
require 'json_scanner'
##
## 構文解析クラス
##
## 使い方:
## parser = JsonParser.new
## obj = parser.parse(File.read('file.json'))
## p obj
##
class JsonParser
def initialize()
@scanner = JsonScanner.new
end
def setup(input)
@scanner.setup(input)
end
def parse(input)
setup(input)
token = @scanner.scan()
unless token == ?{
_raise "not started with '{'."
end
obj = parse_object()
token = @scanner.scan()
unless token.nil?
s = @scanner.token_str
_raise "EOF expected but got #{s.inspect}."
end
return obj
end
def parse_object()
#assert @scanner.token == ?{
obj = {}
while true
## key
token = @scanner.scan()
if token == ?}
if obj.empty? # '}' が '{' の直後なら空 Hash を返す
break
else # '}' が ',' の直後なら文法エラー
_raise "extra ',' found before '}'."
end
end
unless token == :STRING || token == :IDENT
_raise "object key should be string."
end
key = @scanner.token_str
## ':'
token = @scanner.scan()
unless token == ?:
_raise "':' expected."
end
## value
token = @scanner.scan()
value = parse_value(token)
obj[key] = value
## ',' or '}'
token = @scanner.scan()
next if token == ?,
break if token == ?}
_raise "object is not closed by '}'."
end
return obj
end
def parse_array()
#assert @scanner.token == ?[
arr = []
while true
## value
token = @scanner.scan()
if token == ?]
if arr.empty? # ']' が '{' の直後なら空 Array を返す
break
else # ']' が ',' の直後なら文法エラー
_raise "extra ',' found before ']'."
end
end
value = parse_value(token)
arr << value
## ',' or ']'
token = @scanner.scan()
next if token == ?,
break if token == ?]
_raise "array is not closed by ']'."
end
return arr
end
def parse_value(token)
case token
when :STRING ; return @scanner.token_str
when :DECIMAL ; return @scanner.token_str.to_i
when :FLOAT ; return @scanner.token_str.to_f
when :HEXADEC ; return Integer(@scanner.token_str)
when ?{ ; return parse_object()
when ?[ ; return parse_array()
when :TRUE ; return true
when :FALSE ; return false
when :NULL ; return nil
when :IDENT
s = @scanner.token_str
_raise "#{s}: unexpected identifier."
when nil
_raise "unexpected EOF."
else
s = @scanner.token_str
_raise "#{s.dump}: unexpected token."
end
end
def _raise(mesg)
linenum, column = @scanner.get_position()
err = StandardError.new("#{linenum}:#{column}: #{mesg}")
err.set_backtrace(caller())
raise err
end
private :_raise
end
## 構文解析クラスの使い方
if __FILE__ == $0
require 'pp'
input = ARGF.read()
parser = JsonParser.new
obj = parser.parse(input)
pp obj
end終わりに
本稿では、ステートマシンコンパイラである Ragel の簡単な使い方を紹介しました。 また具体的な応用例として、JSON パーサを作成しました。 Ragel を使うと、字句解析部が簡単に作成できます。
ただし Ragel が生成するコードは、C であれば効率がいいのですが、Ruby のコードはそれほど効率がよくありません4。 字句解析部を作るなら、Ruby では StringScanner がありますので、もしかしたらそちらのほうが実行効率がいいかもしれません。 興味のある人は両方試してみてください。 —-