クックパッドを Ruby 2.0.0 に対応させた話
書いた人:村田賢太 (@mrkn)
クックパッドを Ruby 2.0.0 に対応させた話
Ruby 2.0.0-p0 がリリースされて2ヶ月ちょっと経過してます。1この新しい Ruby を皆さんはもう使っているでしょうか。
先日クックパッドが本番環境で使用する Ruby が 2.0.0-p0 にアップグレードされました。アップグレード作業を担当したのは著者です。本稿では、この移行作業で得られた知識を皆さんに紹介します。
目次
- クックパッドを Ruby 2.0.0 に対応させた話
- 目次
- Ruby 2.0.0 に移行するまでの流れ
- Ruby のバージョンアップ作業
- Ruby のバージョンアップした結果
- まとめ
- 著者について
Ruby 2.0.0 に移行するまでの流れ
2011 年 11 月から著者はクックパッドの Ruby 1.9.3 対応を開始しました。当サイトは Ruby Enterprise Edition で運用されていました。諸事情により移行作業は3ヶ月後に一時中断され、他の業務にあたる事になりました。そしてちょうど 1 年後、2012 年 11 月に移行作業を再開し、2013 年 2 月 26 日に完了しました。さらに、そのあとすぐに Ruby 2.0.0 対応を開始し、同年 4 月 9 日に完了しました。
作業開始から終了までの期間は、Ruby 1.9.3 対応では約7ヶ月、Ruby 2.0.0 対応では約 1.5 ヶ月です。この期間、バージョンアップ対応だけをやっているわけではなく、新バージョンのための環境構築、全く異なる別の作業などを並行して行っています。純粋なバージョンアップ作業で必要になった時間は、Ruby 1.9.3 対応では約 4 ヶ月分の時間を使った事になります。Ruby 2.0.0 対応においては、約 2 週間分ほどの時間しか使っていません。
Ruby 2.0.0 対応に要した時間がとても短い理由は、__2.0.0 が 1.9.3 との高い互換性を維持したままリリースされたから__でしょう。
Ruby のバージョンアップ作業
1.9.3 への移行
Ruby Enterprise Edition から Ruby 1.9.3 へ移行する際に出会った問題と、私がとった対策について説明します。
SyntaxError を誘発する非互換性
ここでは 1.8 と 1.9 の間で起きた仕様の変化によって SyntaxError が発生してしまうようになったものを紹介します。
マジックコメント
Ruby 1.9 から m17n が導入され、すべての文字列と正規表現が文字エンコーディングを持つことになりました(参考)。Ruby 1.9 ではスクリプトエンコーディングのデフォルト値が US-ASCII であるため、文字列や正規表現でマルチバイト文字を使用しているファイルにマジックコメントを書く必要がありました。
著者以外のエンジニアは 1.8 を使用しているため、新しく追加されるファイルにマジックコメントが記載されないことが原因の Syntax Error が時々発生していました。著者は以下のスクリプトを使って、リポジトリ内のすべてのファイルを走査し、マジックコメントが必要なファイルに自動的にマジックコメントを入れました。
#! /usr/bin/env ruby
# coding: utf-8
# https://gist.github.com/mrkn/5173137
def has_magic_comment?(content)
if content.lines.first =~ /\A#!/
first_line = content.lines.take(2).last
else
first_line = content.lines.first
end
comment = first_line.sub(/(?:\"(?:[^"]|\\\")*\"|\'(?:[^']|\\\')*\'|[^#]*)#/, '').strip
comment =~ /\b(?:en)?coding\s*:\s*(?:utf|UTF)-?8\b/
end
def insert_magic_comment(path)
content = open(path, 'rb') {|io| io.read } rescue $!
return if Exception === content || content.empty?
content.force_encoding('BINARY') if content.respond_to?(:force_encoding)
unless has_magic_comment?(content)
if content =~ /[^\x00-\x7E]/m
$stderr.puts "inserting magic comment to #{path}"
open(path, 'wb') do |io|
io.puts "# coding: utf-8"
io.write content
end
end
end
end
if ARGV[0] == '--pre-commit'
open("|git diff --cached --name-only HEAD") do |io|
while path = io.gets
path.strip!
next unless path =~ /\.rb$/
insert_magic_comment(path)
end
end
else
require 'find'
Find.find(Dir.pwd) do |path|
next unless path =~ /\.rb$/
insert_magic_comment(path)
end
end
このスクリプトは pwd 以下にある拡張子が .rb のファイルを対象にマジックコメントが必要だったら # coding: utf-8 をファイルの先頭に挿入します。コマンドラインで --pre-commit オプションを指定すると git add されたファイルのみを対象にマジックコメントを挿入するようになっています。git の pre-commit フックから呼び出すときに便利です。
then や do の代わりのコロン
Ruby 1.8 までは、以下に示すように、if や while の条件の後ろにコロン (:) を置く記法が許されていました:
y = y0
while y > height:
x = x0
while x > width:
calculate(x, y, dx, dy)
x += dx
end
y += dy
end
この記法は Ruby 1.9 で削除されたため、上記のコードは Syntax Error になります。
これに対する技術的な対策は特にやっていません。テストを実行して Syntax Error が発生する度に手動でコロンを削除しました。
ブロックパラメータとしてのインスタンス変数
みなさんは 1.8 まで以下のようなブロックパラメータが許されていた事をご存知ですか?
recipes.each do |@recipe|
render 'shared/recipe_detail'
end
そう、インスタンス変数をブロックパラメータにできたんです。びっくりですね。
著者は、このようなコードを、手っ取り早く次のように書き換えて対処しました。 同じような変更を @a_matsuda さんが rails でやっているので、問題ないでしょう(笑)
recipes.each do |recipe| @recipe = recipe
render 'shared/recipe_detail'
end
くそ真面目に対策するなら、partial view template の中まで調べて、view template 内で新しいインスタンス変数を導入しないように修正すべきです。クックパッドの 1.9.3 対応作業では、そこまで真面目にやっていると仕事が終わらない可能性が高かったので手抜きをしました。
消された機能
本セクションでは Ruby 1.9 になって削除された機能をまとめました。
next でメソッドから抜けられない
1.8 までは、return だけでなく、next でもメソッドを抜けることができました。
クックパッドでは Chanko を使って新機能の開発を実施しているため、開発中の多くの機能が Proc クラスのインスタンスで提供されています。それらの新機能は、アプリケーションのメインコードへ結合されるときに、コントローラのアクションや、ヘルパのメソッドへと置換されます。
その際、next を return に書き換えるのを忘れてしまうことがあるらしく、いくつかのメソッドが next でメソッドを抜けるように作られていました。
この問題は、Invalid next エラーが出るため、コードを実行するとすぐに気付けます。
$ ruby -e 'def foo; next; end; foo'
-e:1: Invalid next
-e: compile error (SyntaxError)私は、この Invalid next を見つけるたびに手で置き換えることで対策しました。
Symbol#to_int が消えたイイ話
hash[:symbol]このコードは、hash に :symbol がキーとして含まれていればそれに対応する値を、そうでなければ nil を結果とします。
本当にそうでしょうか?
このコードがそのような振る舞いを示すためには、hash が Hash クラスのインスタンスであるか、それ相当の振る舞いを示すオブジェクトである必要があります。
もし hash が配列や文字列など、整数インデックスだけを受け付けるオブジェクトだったら……そのような場合であっても、Ruby 1.8 ではエラーが起きずに動いてしまいます! その理由は Symbol#to_int が存在するからです。
Ruby 1.9 では、Symbol#to_int が削除されています。そのため hash が配列や文字列である場合に上記のコードはかならずエラーを発生させます。
$ ruby -e '"str"[:sym]'
-e:1:in `[]': no implicit conversion of Symbol into Integer (TypeError)
from -e:1:in`<main>'これはとても良い話です。私はこの仕様変更のおかげで、この移行作業中にテストで発見できなかったバグを見つけて修正しています。バグを生みやすい仕様が是正されることはとても歓迎できる仕様変更だと思います。
Enumerable#enum_with_index
1.8 では、each_with_index と同じ働きをする enum_with_index がありました。これを使っていると NoMethodError が発生するので、その例外を見つけるたびに置き換える方法もあります。しかし、私はその方法はとらず、enum_with_index を git grep コマンドで検索し、発見された行を機械的に置き換える方法で解決しました。メソッド名が独特だからできる技だと思います。
(time .. time).include? time
1.9 から Time#succ が廃止されたことで、両端が Time オブジェクトの Range に対して Range#include? を使って包含関係を調べられなくなりました。これは、Range#cover? を使うよう変更することで対処できます。
この問題に対しては、Ruby Enterprise Edition の場合に以下のような monkey patch を使って警告を出す事で、使用箇所の発見だけでなく、サービス開発者によって新たな使用箇所が追加されることを防ぎました。
class Time
def succ_with_warning(*args)
$stderr.puts "[WARN] Time#succ is obsolete; use time + 1 at #{caller[0]}"
succ_without_warning(*args)
end
alias succ_without_warning succ
alias succ succ_with_warning
end
class Range
def include_with_warn?(obj)
if Time === self.begin
caller.tap do |callstack|
repository_root = File.expand_path('../../../../../../../', __FILE__) + '/'
offending_line = callstack.find {|line|
File.expand_path(line.split(':').first).start_with?(repository_root)
} || callstack.first
$stderr.puts "[WARN] can't iterate from Time since 1.9 at #{offending_line}"
end
end
include_without_warn?(obj)
end
alias include_without_warn? include?
alias include? include_with_warn?
end
Date#step と ActiveSupport::Duration
1.9 から date ライブラリが拡張ライブラリにかわりました。その過程で、Date#step は第2引数に Numeric だけを受け付けるようになりました。そのため、1週間単位の繰り返しを以下のように書けなくなりました。
begin_date.step(end_date, 1.week) do |date|
# ...
end
このようなコードが増えていかないように、以下のモンキーパッチを導入して警告を出し、サービス開発者に注意を促すようにして対応しました。
require 'date'
class Date
def step_with_warn(*args)
unless Numeric === args[1] || args[1].nil?
$stderr.puts "[WARN] non-Numeric object is given for the 2nd argument of step at #{caller[0]}"
end
step_without_warn(*args, &block)
end
alias step_without_warn step
alias step step_with_warn
end
意味が変わったもの
本セクションでは Ruby 1.9 になって意味が変化したものをまとめました。
lambda で生成される Proc オブジェクトの引数マッチング
lambda で作った Proc オブジェクトの引数マッチングが、メソッドの引数マッチングと同じルールに変更されました。そのため、これまで動いていた以下のコードが動かなくなりました。
lambda { }.call(1)これは、任意の引数を受け付けるように変更して対応しました。
多重代入
次のコードを 1.8 と 1.9 の両方で実行してみてください。
a = *[1]
p aRuby 1.8 では 1 が表示されるのに対して、Ruby 1.9 では [1] が表示されます。多重代入のルールが変わったためです。以下のようにカンマを付けることで同じ挙動にできます。
a, = *[1]
p a正規表現の非互換性
1.9 から正規表現エンジンが鬼車に変わりました。鬼車は 1.8 で採用されていた正規表現エンジンよりも多くの機能を持っています。1.9 から導入された m17n にも対応しています。
これはとても良い改善ですが、同時に非互換性が導入され、同じ正規表現が Ruby 1.8 と 1.9 で意味が異なってしまう場合も出ています。
最も大きな影響がありそうな仕様変更が単語構成文字クラスを表す \w とその否定形の \W でしょう。この2つの文字クラスの構成文字種は、Ruby 1.8 までは $KCODE の値によって変化していました。$KCODE が none である場合、単語構成文字は ASCII の範囲に限られ、アルファベットと数字とアンスコ (_) でした。$KCODE が utf8 などマルチバイト文字エンコーディングを意味する値の場合は、ASCII の範囲外の文字も単語構成文字に含まれます。たとえば、ひらがな、カタカナ、漢字などです。
ところが、Ruby 1.9 からは \w と \W が持つ文字が常に ASCII の範囲内に限定されることになりました。その理由は、新しい正規表現処理エンジンが Unicode のプロパティを使って文字クラスを作れるようになったからです。その機能を使うと、ASCII の範囲外の文字も含む単語構成文字クラスは \p{Word} であり、その否定形は \P{Word} になります。
この違いを吸収するため、私は以下のように正規表現を実行時にコンパイルする方法を採用しました。
word = RUBY_VERSION < '1.9' ? '\w' : '\p{Word}'
regex = /#{word}/
正規表現を実行時に作っている理由はコンパイルエラーを避けるためです。以下の方法では、Ruby 1.8 で \p や \P を含む正規表現をコンパイルしようとするため、コンパイルエラーになります。
regex = RUBY_VERSION < '1.9' ? /\w/ : /\p{Word}/
Ruby 1.9 では、正規表現とマッチさせる文字列の文字エンコーディングを気にする必要があります。この話は「独自の String#blank?」の項で詳しく説明します。
ActiveRecord と nil.id
次に示すコードはシンプルな has_many 関係を持つ ActiveRecord のモデルです。
module User < ActiveRecord::Base
belongs_to :group
end
module Group < ActiveRecord::Base
has_many :users
end
ActiveRecord は、User#group に保持されたオブジェクトが DB に保存される際、group.id の結果を group_id カラムに保存しようとします。このとき、User#group に nil が入っていると nil.id が呼ばれ、nil.id が CRuby では 4 になることから、whiny_nils が無効になっていると group_id に 4 が入ってしまう現象が起きることは有名です。
Ruby 1.9 ではこの現象は発生しません。代わりに NoMethodError が発生します。その理由は Object#id メソッドが削除されたからです。2
この問題に対しては、Ruby 1.8 の場合に nil.id でエラーが出ないことの方を問題だと解釈し、以下のようなモンキーパッチを使用して nil.id が呼ばれた場所を検出する方法をとりました。このモンキーパッチは Rails.application.config.whiny_nils を参照するため、initializer の中でロードする必要があります。
if Rails.application.config.whiny_nils
require 'active_support/whiny_nil'
end
if RUBY_VERSION < '1.9'
class NilClass
def id_with_warn(*args)
return 4 unless File.expand_path(caller[0]).starts_with?(Rails.root)
message = "nil.id was called at #{caller[0]}"
if defined? Logger
Logger.error.post('nil.id', message)
else
$stderr.puts message
end
4
end
alias id_without_warn id
alias id id_with_warn
end
end
新ハッシュ記法
Ruby 1.9 から導入された新ハッシュ記法に関連する面白い非互換性があります。
def foo(x)
"foo: #{x}"
end
def bar(x)
"bar: #{x}"
end
p foo bar:baz
上記のコードは 1.8 では foo: bar: baz が表示されます。3ところが 1.9 では bar: というキーに変数 baz の値を対応させたハッシュを引数に foo メソッドを呼び出そうとして、変数 baz が無いため NameError になります。
文字エンコーディング関係
本セクションでは文字エンコーディング関係のことがらをまとめました。
Tempfile のオープンモード
Ruby 1.9 で文字エンコーディングに関する機能が組み込まれた事で、IO オブジェクトにも文字エンコーディング関連の新しい振る舞いが増えています。それは、IO オブジェクトが持つ外部エンコーディングと内部エンコーディングです。外部エンコーディングは IO オブジェクトの向こう側にあるもの (e.g. ファイル) が持つデータのエンコーディングです。IO オブジェクトから読み込んだ文字列は、IO オブジェクトに外部エンコーディングとして指定した文字エンコーディングを持っています。特に指定しない場合、デフォルトの外部エンコーディングは Encoding.default_external で指定された文字エンコーディングになります。入力文字列を外部エンコーディングとは異なる文字エンコーディングへ自動変換する場合は、その変換先の文字エンコーディングを IO オブジェクトの内部エンコーディングに設定します。
このような仕組みが増えたことで、バイナリファイルを開いて作業する際は、ファイルのオープンモードを 'rb' や 'wb' にして明示的にバイナリモードで開くか、ファイルを開いた後で IO#set_encoding を使用して外部エンコーディングを ASCII-8BIT または BINARY に設定する必要があります。
クックパッドには、Eメールで投稿された画像データを処理しているコードがあり、この部分でメールから取り出した画像データを一時的にファイルに書き出して処理しています。一時ファイルを取り扱うために標準ライブラリで提供されている Tempfile を使っているのですが、Tempfile が使用するオープンモードは 'w+' に固定されていて、かつ、Encoding.default_external が UTF-8 になっていたため、画像データを書き込む際に Invalid byte sequence が発生してしまいました。
これの解決方法としては、IO#set_encoding メソッドでエンコーディングを変更する方法と Tempfile.new に encoding オプションを使う方法の2種類があります。既にオープンされた Tempfile オブジェクトが与えられる場合は前者を、自分で Tempfile.new できる場合は後者を採用して解決します。
nkf, kconv, jcode, iconv
Ruby 1.9 から文字エンコーディングの仕組みが組み込まれたことで、1.8 で標準だった kconv, jcode, iconv などの文字エンコーディング関係のライブラリの使用は非推奨になっています。
クックパッドのコードでは、これらと nkf のそれぞれに依存しているコードが散らばっている状態でした。私はそれらを整理し、1.8 での文字エンコーディング関連の処理は NKF だけに依存するようにして、1.9 では原則として組み込みのエンコーディング変換機能のみを使用するように修正したいと考えました。そこで次のモンキーパッチを String クラスに対して導入し、それだけを使用するようにアプリケーションコードを書き換えました。
# Ruby 1.8 に対するモンキーパッチ
class String
alias b dup
def force_encoding(encoding)
self
end
def to_utf8_from_win31j
encode_to_utf8('Windows-31J')
end
def to_win31j_from_utf8
encode_from_utf8('Windows-31J')
end
def to_utf8_from_cp50221
encode_to_utf8('CP50221')
end
def to_cp50221_from_utf8
encode_from_utf8('CP50221')
end
def encode_to_utf8(from_encoding)
nkf_options = case from_encoding
when 'Windows-31J'
'-S'
when 'CP50221'
'-J'
else
raise 'invalid encoding'
end
nkf_options += ' -w -m0 -x'
NKF.nkf(nkf_options, self)
end
def encode_from_utf8(to_encoding)
nkf_options = case from_encoding
when 'Windows-31J'
'-s'
when 'CP50221'
'-j'
else
raise 'invalid encoding'
end
nkf_options += ' -W -m0 -x'
NKF.nkf(nkf_options, self)
end
end
文字エンコーディング変換処理のほとんどの用途は、ガラケーに対応する際の UTF-8 と Windows-31J の間での変換と、メール処理での UTF-8 と CP50221 の間の変換です。そのため、この2つの場合に対しては専用のメソッドを用意しておきました。
次に Ruby 1.9 用のモンキーパッチを示します。1.9 では、nkf と挙動をそろえるために、未定義コードポイントや不正なバイト列に対して空文字でフォールバックするようにしています。
# Ruby 1.9 に対するモンキーパッチ
class String
def b
dup.force_encoding('BINARY')
end
def to_utf8_from_win31j
encode_to_utf8('Windows-31J')
end
def to_win31j_from_utf8
encode_from_utf8('Windows-31J')
end
def to_utf8_from_cp50221
encode_to_utf8('CP50221')
end
def to_cp50221_from_utf8
encode_from_utf8('CP50221')
end
def encode_to_utf8(from_encoding)
encode('UTF-8', from_encoding, :invalid => :replace, :undef => :replace, :replace => '')
end
def encode_from_utf8(to_encoding)
encode(to_encoding, 'UTF-8', :invalid => :replace, :undef => :replace, :replace => '')
end
end
独自の String#blank?
Ruby 1.9 では正規表現も文字エンコーディングを保持します。そのため、正規表現と文字列が持つ文字エンコーディングが比較に対して互換でなければエラーが出てしまいます。
クックパッドで使用している String#blank? は、IDEOGRAPHIC SPACE (U+3000) も空白として扱うようカスタマイズしてあるのですが、文字列自身の文字エンコーディングが UTF-8 ではない場合に incompatible encoding regexp match というエラーが出てしまいました。この問題に対しては、Ruby 1.9 の場合に以下のような String#blank? を使用することで対応しました。
class String
def blank?
case encoding
when Encoding::UTF_8
/\A[\s\u{3000}]*\z/ === self
when Encoding::US_ASCII, Encoding::ASCII_8BIT
/\A\s*\z/ === self
else
begin
self.encode('UTF-8').blank?
rescue
self.dup.force_encoding('BINARY').blank?
end
end
end
end
上記のコードは UTF-8 とバイナリを特別扱いしています。他に良く使用される文字エンコーディングが存在するなら、それも特別扱いすると再帰呼び出しコストを抑えることができるでしょう。
2.0.0 への移行
Ruby 1.9.3 から Ruby 2.0.0 へ移行する際に出会った問題について説明します。
Object#initialize_clone と Object#initialize_dup がプライベートメソッドになった
Ruby 2.0 では Object#initialize_clone と Object#initialize_dup がプライベートメソッドになりました。そのため、Rails にこのパッチを適用する必要がありました。4
スレッド周辺の非互換性
Ruby 2.0.0 ではスレッド周辺の実装が改善されていますが、これが 1.9.3 との非互換性を生み出しています。クックパッドがハマった非互換性は、シグナルハンドラの中で Mutex のロックを取得できなくなったことです。あるシグナルハンドラの中で FluentLogger に情報を記録する処理が存在していたのですが、FluentLogger は書き込み時に Mutex のロックを取得する場合があり、そのため例外が発生してしまいました。
FluentLogger に書き込んでいた情報が現在は必要ない情報であったため、シグナルハンドラを削除して解決させました。
rubygems のバグ
Ruby 2.0.0-p0 に同梱されてる rubygems にバグがあって bson_ext の拡張ライブラリが正常にインストールされない問題が起きました。この問題は 2.0.0-p0 リリース後に ruby_2_0_0 ブランチで修正されました。クックパッドでは、rubygems だけを修正済みのリビジョンに置き換えることで対応しました。
バージョンアップ対応の進め方
Ruby 1.9.3 へのバージョンアップ対応では、常に Ruby Enterprise Edition と Ruby 1.9.3 の両方でテストが通る状態を維持することに努めました。Ruby 2.0.0 へのバージョンアップ対応も同様に、Ruby 1.9.3 と Ruby 2.0.0 の両方でテストが通る状態を維持しながら進めました。
このような方法を採用した理由は、新バージョンへ対応するための変更を「バージョン移行用ブランチ」に溜めず、master ブランチに次々とマージできるようになるからです。
Ruby のバージョンアップでは、バージョン間の差をモンキーパッチで吸収しやすいので、このような方法をとることができます。
一方、Rails のバージョンアップでは、バージョン間差異をモンキーパッチで吸収しにくい為、バージョン移行用のブランチ内で作業する必要があります (本稿で扱っているクックパッドは、Rails がバージョン 1 の頃のコードベースを使い続け、Rails のバージョンアップを何度か実施し、現在は Rails 3.2 系で運用しています)。
Ruby のバージョンアップした結果
Ruby をバージョンアップすることで、2点うれしいことがありました。
1つ目はサービスの平均レスポンスタイムが大きく改善されたことです。以下は、試験環境で計測したレスポンスタイムの比較です。クックパッドは本番環境での平均レスポンスタイムを 200ms 未満にすることを目標にしていますが、Ruby Enterprise Edition を使用していたときは目標を 100ms 以上も越えていることが多かったのに対して、Ruby を 1.9 にバージョンアップしただけで達成でき、かつ EC2 のインスタンス数を減らすこともできました。
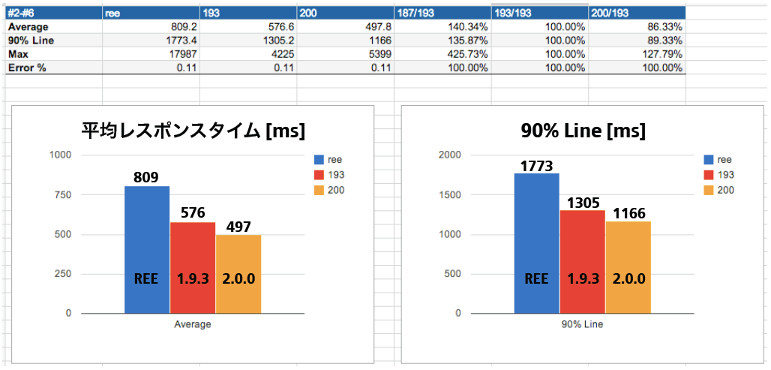
2 つ目は、クックパッドが抱える大量の spec ファイルの実行時間が大幅に短縮されたことです。Ruby Enterprise Edition を使用しているときは、分散 RSpec で使用するワーカーの台数をいくら増やしても実行時間は 14 分を越えていました。ところが Ruby 1.9 へ移行することでサーバ 8 台で 12 分、Ruby 2.0 へ移行するとサーバ 6 台で 8 分台にまで短縮されました。
この結果は、Ruby 1.9 から導入されている YARV によって処理時間が短縮されたこと、さらにメモリの使用効率が非常に良くなっていることが効いていると考えています。メモリの使用傾向が変わったことで、Unicorn のワーカーの使用メモリ量の時間に対する増加の仕方がゆるやかになったため、プロセスが大幅に延命されました。
Ruby のバージョンアップによって、クックパッドのユーザと開発者の双方に大きな恩恵が与えられたことになります。
まとめ
本記事では、Ruby Enterprise Edition 上で動いていた Rails アプリケーションを、Ruby 1.9.3、そして Ruby 2.0.0 に対応させた際に実施した問題対応についてまとめました。この情報が、読者のみなさんのお役に立てれば幸いです。
著者について
村田賢太(クックパッド株式会社)。北海道出身。CRuby のコミッタとして bigdecimal のメンテナンスを担当。2009年に北大で博士号を取得し札幌で就職。2年後に転職し現職へ。クックパッドでは開発基盤エンジニアとして社内のサービス開発エンジニアを幸せにすることで、世界中の料理を楽しくすることに間接的に貢献している。 Twitter: @mrkn