プログラマーのための YAML 入門 (検証編)
書いた人: kwatch
はじめに
YAML (YAML Ain’t Markup Language) とは、データシリアライゼーション用のフォーマットです。読み書きのしやすさを考慮して設計されたため、構造化されたデータを表現するためによく用いられます。「構造化されたデータを表現する」という点では XML と似ていますが、XML と比べて読みやすい、書きやすい、わかりやすいという特徴があります。
今回は、YAML および JSON 用のスキーマバリデータである Kwalify について説明します。Kwalify を使うと、YAML ドキュメントの内容が正しいかどうかを簡単に検証することができます。XML 用のスキーマと比べると Kwalify の機能は少ないですが、最低限の機能は揃っており、またスクリプトで簡単に拡張できるようになっています。
なお本連載では Ruby ユーザにとってのわかりやすさを優先し、用語として「配列」と「ハッシュ」を使ってきました。しかし今回はスキーマを説明するため、YAML の用語である「シーケンス」と「マッピング」を使って説明します。YAML の「シーケンス」は Ruby の「配列」に、また「マッピング」は「ハッシュ」にそれぞれ対応します。ご注意ください。
目次
- はじめに
- Kwalify について
- Kwalify スキーマ詳細
- YAML の機能を使ったスキーマ定義のテクニック
- Kwalify ライブラリ
- スキーマのサンプル
- おわりに
- 著者について
- プログラマーのための YAML 入門 連載一覧
Kwalify について
概要
Kwalify は、YAML 用のスキーマおよびスキーマバリデータです。スキーマとはドキュメントのデータ構造を記述したものであり、スキーマバリデータとはドキュメントがスキーマに沿って正しく書かれているかどうかを検証するツールです。
ドキュメントが正しく記述されているかどうかを調べることは、とても重要です。例をあげると、
- 設定ファイルが正しければプログラムを起動し、誤りがあればエラーを出力してプログラムを終了する。
- 入力データファイルに誤りがあればどの箇所が間違っていたかを報告する。
- 受注データが正しければ受け取り、誤りがあれば拒否する。
など、利用範囲は多岐に渡ります。
スキーマバリデータがあると、YAML ドキュメントが正しく書かれているかどうかを検証できます。例えば次のような YAML ドキュメントがあった場合、内容が正しくないことを検出し、それを報告してくれます。
- name: # ← 名前が入力されていない
email: foo(at)mail.com # ← メールアドレスに「@」が含まれていない
age: twenty # ← 年齢が整数でない
birth: 1985/01/01 # ← 日付のフォーマットが違う
gender: boy # ← 値は M または F のみこういった内容の検証は自分でプログラムを書いてもできますが、スキーマバリデータを使うともっと簡単に検証できます。またスキーマだけでは検証しにくいような複雑なことも、Kwalify では Ruby スクリプトを使って検証できるようになっています (もっというと「宣言的に書きやすいことは宣言的に、宣言的に書きにくいことは手続き的に」書けるようになっています)。
XML では主なスキーマとして DTD、XML Schema、RelaxNG の3つがあり、どれもよく使われています。それに比べると YAML 用のスキーマは貧弱で、過去にいろいろ議論や提案があったようですが、今のところちゃんとした実装があるのは (筆者が知る限り) Kwalify だけです。
Kwalify では以下のような検証ができます。
- データの型
- スカラー (文字列、数値 (整数または浮動小数点)、真偽値、日付、時刻)
- シーケンス
- マッピング
- 必須項目 (SQL の not null 制約に相当)
- 一意性 (SQL の unique 制約に相当)
- 列挙型
- 正規表現によるパターン
- 値の範囲 (最大値と最小値)
- 文字列の長さの範囲 (最大値と最小値)
Kwalify ではスキーマを YAML で表現します (XML Schema や RelaxNG がスキーマを XML で表現するのと同じです)。そのため、アンカーとエイリアスを使ってスキーマ定義を共有したり再帰的に定義することが簡単にできます。また Kwalify では、スキーマ定義の検証も Kwalify 自身で行っています。
また Kwalify は Ruby と Java の実装があります。本稿では Ruby 版を解説しますが、Java 版でも動作は同じです。Java 版については Kwalify ユーザーズガイドを参照してください。
なお Kwalify は「50%-5% の法則」という精神に基づいています。これは「5% の労力で目的の 50% がカバーできる」という発想であり、「80%-20% の法則」(パレートの法則) をより極端にしたものです。そのため Kwalify は RelaxNG や XML Schema などと比べるとできることは少ないですが、シンプルでかつ全体を理解するのも簡単です。また日常使う分には十分なだけの機能を持っています。
インストール
Kwalify のインストールについて説明します。対象となるバージョンは Kwalify 0.5.1 です。
なおインストール例は一般的な UNIX 環境で bash を使った場合とします。
- RubyGems をインストールしている場合は、root 権限で「gem install –remote kwalify」とタイプしてください。
$ sudo gem install --remote kwalify- RubyGems はインストールしてないが root 権限がある場合は、kwalify_0.5.1.tar.bz2 をダウンロードし、同梱されている setup.rb を使って次の手順でインストールしてください。
### Kwalify のアーカイブを解凍
$ tar xjf kwalify_0.5.1.tar.bz2
$ cd kwalify_0.5.1/
### 同梱の setup.rb を使ってインストール
$ ruby setup.rb config
$ ruby setup.rb setup
$ sudo ruby setup.rb install- RubyGems をインストールしてなくて root 権限もない場合は、kwalify_0.5.1.tar.bz2 をダウンロードし、Kwalify のスクリプトとライブラリを適切なディレクトリに手動でコピーしてください。
### Kwalify のアーカイブを解凍
$ tar xjf kwalify_0.5.1.tar.bz2
$ cd kwalify_0.5.1/
### スクリプトを $HOME/bin にコピー
$ mkdir -p $HOME/bin
$ cp -a bin/* $HOME/bin
$ export PATH=$PATH:$HOME/bin
### ライブラリを $HOME/lib/ruby にコピー
$ mkdir -p $HOME/lib/ruby
$ cp -a lib/* $HOME/lib/ruby
$ export RUBYLIB=$HOME/lib/ruby- または同梱されている contrib/inline-require を使うと、Kwalify のライブラリとスクリプトをひとつにまとめてくれますので、これを $HOME/bin などにコピーしてもいいでしょう。
### Kwalify のアーカイブを解凍
$ tar xjf kwalify_0.5.1.tar.bz2
$ cd kwalify_0.5.1/
### contrib/inline-require を実行
$ unset RUBYLIB
$ ruby contrib/inline-require -I ./lib bin/kwalify > $HOME/bin/kwalify
### できたスクリプトを実行可能にする
$ chmod a+x $HOME/bin/kwalify使い方
Kwalify の使い方を簡単に説明しておきます。
Kwalify の使い方は主に2つあります。スキーマファイルを指定して YAML ドキュメントを検証する場合と、スキーマファイル自身を検証する場合です。
## YAML ドキュメントを検証するとき
$ kwalify [...options...] -f スキーマファイル ドキュメント1 ドキュメント2 ...
## スキーマファイル自身を検証するとき
$ kwalify [...options...] -m スキーマファイルまた以下のようなコマンドオプションが指定できます。
- -h, –help
- ヘルプを表示
- -v
- バージョンを表示
- -s
- サイレントモード (表示を最小限に押さえる)
- -f schema.yaml
- スキーマファイル
- -m
- メタバリデーション (スキーマファイル自身を検証する)
- -t
- タブ文字を 8 桁区切りの半角スペースに展開する
- -l
- エラー箇所の行番号を表示する (注:まだ実験的)
- -E
- Emacsが解釈できるフォーマットでエラーを出力する (C-x ` でジャンプできる)
Kwalify スキーマ詳細
Kwalify では、スキーマ定義も YAML 形式で記述します。
このセクションでは、Kwalify のスキーマについて説明します。
シーケンス
文字列のシーケンスをあらわすスキーマは次のようになります。
schema01.yaml : 文字列のシーケンス
\{\{*type: seq*\}\} # データ型はシーケンス
\{\{*sequence:*\}\} # シーケンスの要素は
- type: str # データ型が文字列
ポイントは次のとおりです。
- 「type: seq」は、全体がシーケンスであることを表します。
- シーケンスの要素は「sequence:」の下に記述します。この場合は「type: str」なので、文字列になります。
- 「type: seq」のとき、「sequence:」は省略できません。
- 「sequence:」には要素をひとつしか記述できません。そのため、「文字列または日付のシーケンス」のような指定はできません。
次の例は、上のスキーマに適合する YAML ドキュメントです。ドキュメントがスキーマに適合することを、一般に「妥当である (valid)」といいます。
valid01.yaml : 妥当な YAML ドキュメント
- foo
- bar
- bazKwalify を使って、実際に検証してみましょう。「valid.」と表示されれば成功です。
実行結果 :
$ kwalify -f schema01.yaml valid01.yaml
valid01.yaml#0: valid.次に、上のスキーマに適合しない YAML ドキュメントの例を示します。ドキュメントがスキーマに適合しないことを、一般に「妥当でない (invalid)」といいます。
invalid01.yaml : 妥当でない YAML ドキュメント
- foo
- 123 # ← 文字列ではなく数値が指定されている
- bazこれを、Kwalify を使って検証してみます。「INVALID」と表示されて、妥当でないことがわかります。
実行結果 :
$ kwalify -f schema01.yaml invalid01.yaml
invalid01.yaml#0: INVALID
- [/1] '123': not a string.妥当でなかった箇所は「/1」のように YPath 形式で示されます。この場合だと、シーケンスにおける 2 番目の要素 (YPath では先頭が 0 から始まるため) が文字列ではないと表示されています。
なお Kwalify では、妥当でなかった箇所の行番号をデフォルトでは表示しません。これは、Syck の YAML パーサが YAML ドキュメントをパースしたあとに行番号の情報を捨ててしまうためです。コマンドオプション「-l」をつけると、パース後も行番号を保持する独自の YAML パーサを使って、エラー箇所の行番号を表示します。
$ kwalify -lf schema01.yaml invalid01.yaml
invalid01.yaml#0: INVALID
- (line 2) [/1] '123': not a string.この YAML パーサは所詮「なんちゃってパーサ」であり、あまり信用できるものではありません。しかし本稿で説明するくらいのドキュメントなら問題なくパースできるようですので、以降では「-l」オプションをつけて行番号を表示させてみます。
マッピング
マッピングを表すスキーマは次のようになります。
schema02.yaml : マッピングを表すスキーマ
\{\{*type: map*\}\} # マッピング型
\{\{*mapping:*\}\}
"name":
type: str # 文字列型
required: yes # 必須である
"email":
type: str # 文字列型
pattern: /@/ # パターンとして「@」を含む
"age":
type: int # 整数型
"birth":
type: date # 日付型
ポイントは次のとおりです。
- 「type: map」は、全体がマッピングであることを表します。
- マッピングの要素は「mapping:」の下に記述します。この場合では、次のようになります。
- キー「name」は文字列型で、必須要素 (省略できない)
- キー「email」は文字列型で、パターンとして「@」を含む
- キー「age」は整数型
- キー「birth」は日付型
- 「type: map」のとき、「mapping:」は省略できません。
- キーの名前は「”…“」で囲む必要はありませんが、見やすさのために囲んでおいたほうがいいでしょう。
妥当な YAML ドキュメントの例は次のようになります。
valid02.yaml : 妥当な YAML ドキュメント
name: foo
email: foo@mail.com
age: 20
birth: 1985-01-01検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema02.yaml valid02.yaml
valid02.yaml#0: valid.妥当でない YAML ドキュメントの例は次のようになります。
invalid02.yaml : 妥当でない YAML ドキュメント
name: # 値が設定されていない
email: foo(at)mail.com # 「@」を含んでいない
age: twenty # 整数でない
birth: Jun 01, 1985 # 日付の形式が正しくない検証すると次のようなエラーがでます。
実行結果 :
$ kwalify -lf schema02.yaml invalid02.yaml
invalid02.yaml#0: INVALID
- (line 1) [/name] value required but none.
- (line 2) [/email] 'foo(at)mail.com': not matched to pattern /@/.
- (line 3) [/age] 'twenty': not a integer.
- (line 4) [/birth] 'Jun 01, 1985': not a date.マッピングを要素とするシーケンス
マッピングを要素とするようなシーケンスを考えます。これを表すスキーマの例は次のようになります。
schema03.yaml :
\{\{*type: seq*\}\} # シーケンス型
\{\{*sequence:*\}\} # シーケンスの要素
- \{\{*type: map*\}\} # マッピング型
\{\{*mapping:*\}\} # マッピングの要素
"name":
type: str
required: true
"email":
type: str
妥当な YAML ドキュメントの例は次のようになります。
valid03.yaml : 妥当な YAML ドキュメント
- name: foo
email: foo@mail.com
- name: bar
email: bar@mail.net
- name: baz
email: baz@mail.org検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema03.yaml valid03.yaml
valid03.yaml#0: valid.妥当でない YAML ドキュメントの例は次のようになります。
invalid03.yaml : 妥当でない YAML ドキュメント
- name: foo
email: foo@mail.com
- naem: bar # 「name:」が「naem:」になっている
email: bar@mail.net
- name: baz
mail: baz@mail.org # 「email:」が「mail:」になっている検証すると次のようなエラーがでます。
実行結果 :
$ kwalify -lf schema03.yaml invalid03.yaml
invalid03.yaml#0: INVALID
- (line 3) [/1] key 'name:' is required.
- (line 3) [/1/naem] key 'naem:' is undefined.
- (line 6) [/2/mail] key 'mail:' is undefined.シーケンスを要素とするマッピング
今度は逆に、シーケンスを要素とするマッピングの例です (実際には、「マッピングを要素とするシーケンスを要素とするマッピング」の例です)。
schema04.yaml : シーケンスを要素とするマッピングのスキーマ
\{\{*type: map*\}\} # マッピング型
\{\{*mapping:*\}\} # マッピングの要素
"company":
type: str
required: yes
"email":
type: str
"employees":
\{\{*type: seq*\}\} # シーケンス型
\{\{*sequence:*\}\} # シーケンスの要素
- type: map # マッピング型
mapping: # マッピングの要素
"code":
type: int
required: yes
"name":
type: str
required: yes
"email":
type: str
妥当な YAML ドキュメントの例は次のようになります。
valid04.yaml : 妥当な YAML ドキュメント
company: Ruby lab.
email: webmaster@ruby-lab.com
employees:
- code: 101
name: foo
email: foo@ruby-lab.com
- code: 102
name: bar
email: bar@ruby-lab.com検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema04.yaml valid04.yaml
valid04.yaml#0: valid.妥当でない YAML ドキュメントの例は次のようになります。
invalid04.yaml : 妥当でない YAML ドキュメント
company: ruby Lab.
email: webmaster@ruby-lab.com
employees:
- code: A101 # 値が整数ではない
name: foo
email: foo@ruby-lab.com
- code: 102
name: bar
mail: bar@ruby-lab.com # 「email:」が「mail:」になっている検証すると次のようなエラーが出ます。
実行結果 :
$ kwalify -lf schema04.yaml invalid04.yaml
invalid04.yaml#0: INVALID
- (line 4) [/employees/0/code] 'A101': not a integer.
- (line 9) [/employees/1/mail] key 'mail:' is undefined.一意制約
「unique:」を使うと、シーケンスやマッピングの要素に対して一意制約をつけることができます。これは SQL の unique 制約と同じです。 次の例は、マッピングの要素とシーケンスの要素に一意制約をつけた例です。
schema05.yaml : 一意制約を使ったスキーマ
type: seq
sequence:
- type: map
required: yes
mapping:
"name":
type: str
required: yes
\{\{*unique: yes*\}\} # マッピングの要素に対して一意制約
"email":
type: str
"groups":
type: seq
sequence:
- type: str
\{\{*unique: yes*\}\} # シーケンスの要素に対して一意制約
妥当な YAML ドキュメントの例は次のようになります。
valid05.yaml : 妥当な YAML ドキュメント
- name: foo
email: admin@mail.com
groups:
- users
- foo
- admin
- name: bar
email: admin@mail.com
groups:
- users
- admin
- name: baz
email: baz@mail.com
groups:
- users検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema05.yaml valid05.yaml
valid05.yaml#0: valid.妥当でない YAML ドキュメントの例は次のようになります。
invalid05.yaml : 妥当でない YAML ドキュメント
- name: foo
email: admin@mail.com
groups:
- foo
- users
- admin
- foo # 値が重複している
- name: bar
email: admin@mail.com
groups:
- admin
- users
- name: bar # 値が重複している
email: baz@mail.com
groups:
- users検証すると次のようなエラーがでます。
実行結果 :
$ kwalify -lf schema05.yaml invalid05.yaml
invalid05.yaml#0: INVALID
- (line 7) [/0/groups/3] 'foo': is already used at '/0/groups/0'.
- (line 13) [/2/name] 'bar': is already used at '/1/name'.制約とルール
Kwalify のスキーマで指定できる制約は次のとおりです。
- 「required:」‥‥値が必須かどうかを表します。真偽値を指定します。デフォルトは偽です。
- 「enum:」‥‥とり得る値を列挙して指定します。スカラーのシーケンスを指定します。
- 「pattern:」‥‥文字列のパターンを指定します。正規表現のように「/…./」という形式で指定します。
- 「type:」‥‥値の型を指定します。省略されたときは「str」とみなされます。以下が指定できます。
- str (文字列)
- int (整数)
- float (浮動小数点)
- number (int または float)
- text (str または number)
- bool (真偽値)
- date (日付)
- timestamp (日付と時刻)
- seq (シーケンス)
- map (マッピング)
- scalar (スカラー)
- any (どんなデータでも可)
- 「range:」‥‥値がとり得る範囲をスカラーのマッピングで指定します。「{max: 10, min: 0}」のようにフロースタイルを使うのがよいでしょう。キーとしては次が指定できます。
- max (最大値、その値を含める)
- min (最小値、その値を含める)
- max-ex (最大値、その値を含めない)
- min-ex (最小値、その値を含めない)
- 「length:」‥‥文字列の長さを整数のマッピングで指定します。「{max: 16, min: 8}」のようにフロースタイルを使うのがよいでしょう。「range:」と同じキー (max, min, max-ex, min-ex) が指定できます。
-
「assert:」‥‥値が守るべき条件を式で指定します。このとき、値は「val」という変数で指定し、例えば「assert: val < 0 10 < val」のように指定します。なおこの機能は実験的であり、将来変更される可能性があります。 - 「unique:」‥‥シーケンスまたはマッピングにおいて、値が一意であることを表します。真偽値を指定します。デフォルトは偽です。
- 「name:」‥‥そのルールに名前をつけます (ルールについては後述)。名前をつけるのが目的であり、値の検証は行いません。文字列を指定します。
- 「desc:」‥‥そのルールの簡単な説明をつけます。値の検証では使われません。文字列を指定します。
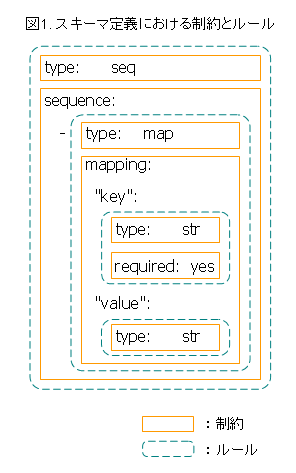
Kwalify では、制約が集まったひとかたまりをルールと読んでいます (図1参照)。シーケンスまたはマッピングを使うことでルールをネストさせることができ、スキーマはネストしたルールで表されます。またルールに名前をつけておくと、Ruby スクリプトからそのルールを参照できます (これについては後ほど説明します)。
次の例は、様々な制約を使ったスキーマの例です。
schema06.yaml : 様々な制約を使ったスキーマ
name: address-book # 名前
desc: アドレス帳 # 説明
type: seq
sequence:
- type: map
mapping:
"name":
type: str
required: yes # 必須項目
"email":
type: str
required: yes # 必須項目
pattern: /@/ # パターン
"password":
type: str
length: { max: 16, min: 8 } # 長さ指定
"age":
type: int
range: { max: 30, min: 18 } # 範囲指定
# or assert: 18 <= val && val <= 30 # 条件式
"blood":
type: str
enum: # 列挙
- A
- B
- O
- AB
"birth":
type: date
"memo":
type: any # データ型は任意
妥当でない YAML ドキュメントの例は次のようになります。
invalid06.yaml : 妥当でない YAML ドキュメント
- name: foo
email: foo(at)mail.com # 「@」が含まれない
password: xxx123 # 長さが短すぎる
age: twenty # 整数でない
blood: a # 値が小文字
birth: 1985-01-01
- given-name: bar # 不明なキー
family-name: Bar # 不明なキー
email: bar@mail.net
age: 15 # 値が小さすぎる
blood: AB
birth: 1980/01/01 # 日付の形式が違う検証すると次のようなエラーが出ます。
実行結果
$ kwalify -lf schema06.yaml invalid06.yaml
invalid06.yaml#0: INVALID
- (line 2) [/0/email] 'foo(at)mail.com': not matched to pattern /@/.
- (line 3) [/0/password] 'xxx123': too short (length 6 < min 8).
- (line 4) [/0/age] 'twenty': not a integer.
- (line 5) [/0/blood] 'a': invalid blood value.
- (line 7) [/1/given-name] key 'given-name:' is undefined.
- (line 7) [/1] key 'name:' is required.
- (line 8) [/1/family-name] key 'family-name:' is undefined.
- (line 10) [/1/age] '15': too small (< min 18).
- (line 12) [/1/birth] '1980/01/01': not a date.YAML の機能を使ったスキーマ定義のテクニック
YAML では標準で以下のような機能が使用できます。
- アンカーとエイリアスを使ってデータを共有する
- マッピングのデフォルト値を指定する
- マッピングに他のマッピングをマージする
このセクションでは、これらの機能を使ったスキーマ定義のテクニックを紹介します。
ルールの共有
YAML には、データに「印」をつけておき、他の場所からそのデータを参照することができます。これをアンカーとエイリアスといいます。
例えば次のような YAML ドキュメントがあるとします。
- \{\{*&a*\}\} # アンカー
name: foo
parent: ~
- name: bar
parent: \{\{**a*\}\} # エイリアス
- name: baz
parent: \{\{**a*\}\} # エイリアス
これは次のような Ruby スクリプトと同じです。
foo = \{\{*a*\}\} = { "name"=>"foo", "parent"=>nil }
bar = { "name"=>"bar", "parent"=>\{\{*a*\}\} }
baz = { "name"=>"baz", "parent"=>\{\{*a*\}\} }
[ foo, bar, baz ]
アンカーとエイリアスを使うと、ひとつのルールを複数の箇所で共有することができます。次の例では著作者についてのルールを翻訳者でも共有しています。
schema07.yaml : ルールを共有するスキーマ
desc: 書籍リスト
type: seq
sequence:
- type: map
mapping:
"title":
type: str
required: yes
"author": \{\{*&persons*\}\} # アンカー
type: seq
sequence:
- type: str
"translator": \{\{**persons*\}\} # エイリアス
"publisher":
type: str
"year":
type: int
妥当な YAML ドキュメントの例は次のようになります。
valid07.yaml : 妥当な YAML ドキュメントの例
- title: コンピュータの構成と設計
author:
- John L. Hennessy
- David A. Patterson
translator:
- 成田 光彰
publisher: 日経BP社
year: 1999
- title: プログラミングRuby―達人プログラマーガイド
author:
- David Thomas
- Andrew Hunt
translator:
- 田和 勝
- まつもと ゆきひろ
publisher: ピアソンエデュケーション
year: 2001検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema07.yaml invalid07.yaml
valid07.yaml#0: valid.再帰的なルールの定義
アンカーとエイリアスを使うと、再帰的なルールを定義することもできます。木構造のようなデータを表現するときに便利です。
次の例では、タスクが複数のサブタスクから構成され、かつタスクとサブタスクが同じルールを共有することで、再帰的な定義となっています。
schema08.yaml : 再帰的なルールの定義
\{\{*&task*\}\} # アンカー
desc: 作業分解図
type: map
mapping:
"name": { type: str, required: yes }
"assigned": { type: str }
"deadline": { type: date }
"subtasks":
type: seq
sequence:
- \{\{**task*\}\} # エイリアス
妥当な YAML ドキュメントの例は次のようになります。
valid08.yaml : 妥当な YAML ドキュメント
name: まんがを描く
deadline: 2005-12-08
subtasks:
- name: 調査
deadline: 2005-12-01
subtasks:
- name: ネットで検索
- name: 図書館で資料をコピー
assigned: 編集者
- name: 関係者にインタビュー
assigned: 作者
- name: ネーム
deadline: 2005-12-03
- name: 下絵
deadline: 2005-12-05
- name: ペン入れ
assigned: アシ1
deadline: 2005-12-06
- name: 仕上げ
assigned: アシ2
deadline: 2005-12-07検証結果は次のとおりです。
実行結果 :
$ kwalify -lf schema11.yaml valid08.yaml
valid08.yaml#0: valid.デフォルトルール
YAML では、マッピングのデフォルト値を指定できます。キーとして「=」を使用すると、その値がマッピングのデフォルト値として使われます。
例えば次の YAML ドキュメントがあるとします。
A: 10
B: 20
\{\{*=*\}\}: -1 # デフォルト値
これは次の Ruby コードと同じです。
map1= {"A"=>10, "B"=>20}
\{\{*map1.default = -1*\}\}
YAML のこの機能を使って、Kwalify ではマッピングにおいて一致するキーの名前が見つからなかった場合のデフォルトルールを指定できるようになっています。これは、キー名が事前にはわからない場合に使用します。
例えば、アプリケーションの設定ファイルを YAML 形式で書くことにしたとします。設定ファイルには、ユーザが独自のプロパティ名とその値を指定できるようにします。
通常であれば、次のように名前と値を別々に定義するでしょう。
properties:
- name: tmpdir
value: /tmp
- name: logdir
value: /var/logこれを、次のように「名前: 値」にすることで、より簡潔な記述にしたいとします。
properties:
tmpdir: /tmp
logdir: /var/logこのとき問題になるのは、マップのキーが何になるか、事前にはわからないことです。これではスキーマ定義を書くことができません。
このようなときは、キーに「=」を指定することでデフォルトのルールを指定します。こうすることで、任意のキーにマッチするようになります。
schema09.yaml : デフォルトのルールを指定したスキーマ
type: map
mapping:
"properties":
type: map
mapping:
\{\{*=*\}\}: # 任意のキーにマッチ
type: any # 値はどんなデータ型でもよい
また他のキーと共に使用することもできます。次の例は、アドレス帳に任意のキーと値を追加できるようにした例です。
schema10.yaml : ユーザが自由にキーと値を追加できるアドレス帳
type: seq
sequence:
- type: map
mapping:
"name":
type: str
required: yes
"email":
type: str
"birth":
type: date
\{\{*=*\}\}: # キーが「name」「email」「birth」以外の場合
type: any # 値はどんなデータ型でもよい
デフォルトルールは、いわばどんなキーにもマッチするルールです。そのため、これを使うとキーのタイプミスが発見できなくなります。それを考慮したうえでお使いください。
ルールのマージと差分定義
YAML では、「<<」を使って複数のマッピングをマージする機能があります。またマージしたマッピングでキーと値の上書や追加ができます。
例えば次のような YAML ドキュメントがあるとします。
- &m1
A: 10
B: 20
- \{\{*<<*\}\}: *m1 # マージ
A: 15 # 上書き
C: 30 # 追加
これは次の Ruby コードと同じです。
m1 = {"A"=>10, "B"=20}
m2 = {}
\{\{*m2.update(m1)*\}\} # マージ
m2["A"] = 15 # 上書き
m2["C"] = 30 # 追加
[m1, m2]
また複数のマッピングをマージすることができます。 例えば次のような YAML ドキュメントがあるとします。
- &m1
A: 10
B: 20
- &m2
C: 30
D: 40
- \{\{*<<: [*m1, *m2]*\}\} # 複数のマッピングをマージ
これは次の Ruby コードと同じです。
m1 = {"A"=>10, "B"=>20}
m2 = {"C"=>10, "D"=>20}
m3 = {}
\{\{*m3.update(m1)*\}\} # マージ
\{\{*m3.update(m2)*\}\} # マージ
[m1, m2, m3]
YAML のこの機能を使うと、Kwalify でルールのマージや差分定義(上書きと追加)ができます。次の例では、グループについてのルールに追加・上書きすることで、ユーザについてのルールを定義しています。
schema11.yaml : ルールのマージと差分定義を行う例
type: map
mapping:
"group":
type: map
mapping:
"name": \{\{*&name*\}\}
type: str
required: yes
"email": \{\{*&email*\}\}
type: str
pattern: /@/
required: no
"user":
type: map
mapping:
"name":
\{\{*<<: *name*\}\} # マージ
\{\{*length: { max: 16 }*\}\} # 追加
"email":
\{\{*<<: *email*\}\} # マージ
\{\{*required: yes*\}\} # 上書き
次のような、妥当でない YAML ドキュメントで試してみましょう。
invalid11.yaml : 妥当でない YAML ドキュメントの例
group:
name: foo
email: foo@mail.com
user:
name: toooooo-looooong-name検証してみると、次のようなエラーがでます。
実行結果 :
$ kwalify -lf schema11.yaml invalid11.yaml
invalid11.yaml#0: INVALID
- (line 4) [/user] key 'email:' is required.
- (line 5) [/user/name] 'toooooo-looooong-name': too long (length 21 > max 16).Kwalify ライブラリ
このセクションでは、Ruby スクリプトから Kwalify を使う方法を説明します。
Ruby スクリプトから Kwalify を使う
Ruby スクリプトにおいて、Kwalify のライブラリを使って YAML ドキュメントを検証するには、Kwalify::Validator クラスを使います。
script1.rb : Kwalify ライブラリを使って検証するサンプル
require 'kwalify'
## スキーマファイルを読み込み、バリデータを作成する。
## スキーマ定義にエラーがあると、例外 Kwalify::SchemaError が発生する。
schema = YAML.load_file('schema.yaml')
\{\{*validator = Kwalify::Validator.new(schema)*\}\}
## YAML ドキュメントを読み込み、バリデータで検証する。
## エラーがあれば Kwalify::ValidationError の配列が、なければ空の配列が返される。
document = YAML.load_file('document.yaml')
\{\{*errors = validator.validate(document)*\}\}
if !errors || errors.empty?
puts "valid."
else
errors.each do |error|
puts "[#{error.path}] #{error.message}"
end
end
この例でわかるように、Kwalify では YAML ドキュメントをパースするときに検証するのではなく、読み込んだあとの YAML ドキュメントに対して検証を行います。そのため、Syck の YAML パーサのように行番号をパース中にしか保持しないパーサだと、エラー箇所の行番号がわかりません。
コマンドラインオプション「-l」と同じようにエラー箇所を行番号で表示したい場合は、Syck の YAML パーサではなく Kwalify::YamlParser を使用する必要があります。ただしこのパーサは実験的であり、YAML の仕様をすべて満たしているわけではありませんので注意してください。
script2.rb : Kwalify::YamlParser を使って行番号を表示するサンプル
## Kwalify::Parse を使って YAML ドキュメントを読み込む。
## (このパーサは行番号を保持している。)
str = ARGF.read()
\{\{*parser = Kwalify::Parser.new(str)*\}\}
\{\{*document = parser.parse()*\}\}
## スキーマファイルを読み込み (これは Syck を使ってもよい)、
## バリデータを作成して検証する。
schema = YAML.load_file('schema.yaml')
\{\{*validator = Kwalify::Validator.new(schema)*\}\}
\{\{*errors = validator.validate(document)*\}\}
## エラーがあれば、行番号を設定して表示する。
## 行番号を設定するには、Kwalify::Parser が必要。
if !errors || errors.empty?
puts "valid."
else
\{\{*parser.set_errors_linenum(errors)*\}\} # YPath をもとに行番号を設定
errors.sort.each do |err| # 行番号でソートし、表示する
print "line %d: path %s: %s" % [err.linenum, err.path, err.message]
end
end
また読み込んだあとの YAML ドキュメントは配列とハッシュとスカラーの組み合わせであり、これは JSON と同じです。つまり JSON を読み込んで、それを Kwalify で検証することが可能です。ほかにも、CGIパラメータの検証などに使用できるでしょう。
なお Kwalify のバリデータはステートレスであり、ひとつのバリデータで複数の YAML ドキュメントを検証することができます。YAML ドキュメントごとにバリデータを生成する必要はありません。
Ruby スクリプトでスキーマファイルを検証する
スキーマファイル自身が正しいかどうかを検証するバリデータを「メタバリデータ」と呼んでいます。メタバリデータは Kwalify::MetaValidator.instance() または Kwalify.meta_validator() で取得できます。また検証の仕方はふつうのバリデータと同じです。
script3.rb : スキーマファイル自身を検証するサンプル
## メタバリデータを取得する
require 'kwalify'
\{\{*meta_validator = Kwalify::MetaValidator.instance()*\}\}
## スキーマファイルを検証する
schema = File.load_file('schema.yaml')
\{\{*errors = meta_validator.validate(schema)*\}\}
if !errors || errors.empty?
puts "valid."
else
errors.each do |error|
puts "- [#{error.path}] #{error.message}"
end
end
フックメソッドを用いて独自の検証を行う
Kwaify では、Kwalify::Validator#validate_hook() というフックメソッドが用意されています。これは、Kwalify::Validator#validate() から呼ばれるメソッドであり、プログラマーがサブクラスで拡張できます。
フックメソッドを用いると、複数の項目にまたがるような検証など、Kwalify のスキーマでは検証しにくいような内容を検証できます。 例えば次の例では、「アンケートで『悪い』と答えた人はその理由を書かなければならない」という検証をしていますが、これは「アンケートの答え」によって「理由」が必須かそうでないかが変わっています。
script4.rb : フックメソッドの例
#!/usr/bin/env ruby
require 'kwalify'
require 'yaml'
## Kwalify::Validator のサブクラスを定義
class AnswersValidator < Kwalify::Validator
## スキーマ定義を読み込む
@@schema = YAML.load_file('answers.schema.yaml')
def initialize()
super(@@schema)
end
## Validator#validate() から呼び出されるフックメソッド
def \{\{*validate_hook(value, rule, path, errors)*\}\}
# ルールの名前が 'Answer' である場合だけ実行
case \{\{*rule.name*\}\}
when \{\{*'Answer'*\}\}
# 解答が 'bad' であれば、理由の記入が必須である
if value['answer'] == 'bad'
if value['reason'] == nil || value['reason'].empty?
msg = "reason is required when answer is 'bad'."
\{\{*errors << Kwalify::ValidationError.new(msg, path)*\}\}
end
end
end
end
end
## YAML ドキュメントを読み込む
## (エラー行番号を表示するために、Kwalify::YamlParser を使う。)
input = ARGF.read()
parser = Kwalify::YamlParser.new(input)
document = parser.parse()
## バリデータを作成し、検証する
validator = AnswersValidator.new
errors = validator.validate(document)
## エラーがあれば行番号つきで表示する
if !errors || errors.empty?
puts "Valid."
else
parser.set_errors_linenum(errors)
errors.sort.each do |error|
puts " - line #{error.linenum}: [#{error.path}] #{error.message}"
end
end
スキーマは次のようになります。「name:」を使ってルールに名前をつけ、それを上のスクリプトで参照しているのがポイントです。
answers.schema.yaml : スキーマ
type: map
mapping:
answers:
type: seq
sequence:
- type: map
\{\{*name: Answer*\}\} # ルールに名前をつける
mapping:
"name":
type: str
required: yes
"answer":
type: str
required: yes
enum:
- good
- not bad
- bad
"reason":
type: str
妥当でない YAML ドキュメントの例は次のようになります。
answers.data.yaml : 妥当でない YAML ドキュメント
answers:
- name: Foo
answer: good
- name: Bar
answer: bad #「answer:」が bad のときは「reason:」が必要
- name: Baz
answer: not badスクリプトによる検証結果は次のとおりです。
実行結果 :
$ ruby script4.rb answers.data.yaml
- line 4: [/answers/1] reason is required when answer is 'bad'.スキーマによる検証とプログラムによる検証を比べると、一般的に次のような特徴があります。
- スキーマによる検証は「宣言的」であり、記述が簡単なかわりに複雑な検証はできません。
- プログラムによる検証は「手続き的(逐次的)」であり、複雑な検証ができるかわりに記述は煩雑になります。
Kwalify では、宣言的に書きやすいことは宣言的に、宣言的に書くのが難しいことは手続き的に書くことができるため、両者のいいとこどりができます。
なお Kwalify のバリデータはステートレスとなっていますが、フックメソッドの中でインスタンス変数を使う場合はステートフルになるので注意してください。
スキーマのサンプル
Kwalify のアーカイブには、スキーマのサンプルがいくつか用意されています。
- examples/address-book ‥‥ アドレス帳のサンプルです。
- examples/invoice ‥‥ インボイス (受注データのようなもの) のスキーマです。YAMLホームページ からの拝借です。
- examples/tapkit ‥‥ TapKit におけるモデルファイルのスキーマです。
これとは別に、前回作成した creatable ツールのスキーマを定義してみました。ポイントは次の通りです。
- 「defaults:」と「tables:」ではどちらも「columns:」を使うので、アンカーとエイリアスを使って同じルールを共有しています。
- 外部キーを表す「ref:」は再帰的な定義になるので、これもアンカーとエイリアスを使います。
Kwalify ではスキーマを YAML 形式で定義するので、アンカーとエイリアスを使ってこのようなことが簡単にできます。
creatable.schema.yaml : creatable のためのスキーマ
type: map
mapping:
"defaults":
type: map
mapping:
"columns":
type: seq
sequence:
- \{\{*&column-rule*\}\} # アンカー
type: map
mapping:
"name": { type: str, required: yes }
"desc": { type: str }
"type": { type: str }
"width": { type: int }
"primary-key": { type: bool }
"serial": { type: bool }
"not-null": { type: bool }
"unique": { type: bool }
"enum":
type: seq
sequence:
- type: scalar
\{\{*"ref": *column-rule*\}\} # エイリアスで再帰的な定義
"tables":
type: seq
sequence:
- type: map
mapping:
"name": { type: str, required: yes }
"class": { type: str }
"desc": { type: str }
"columns":
type: seq
sequence:
- \{\{**column-rule*\}\} # エイリアスでルールを共有
前回のデータファイル (datafile.yaml) を使って検証してみましょう。
実行例 :
$ kwalify -lf creatable.schema.yaml datafile.yaml
datafile.yaml#0: valid.おわりに
本稿では、YAML 用のスキーマバリデータである Kwalify について説明しました。Kwalify は次のような特徴を持ちます。
- Kwalify では次のような検証が可能です。
- データの型 (シーケンス、マッピング、スカラー)
- 必須項目 (SQL の not null 制約に相当)
- 一意性 (SQL の unique 制約に相当)
- 列挙型
- 正規表現によるパターン
- 値の範囲 (最大値と最小値)
- 文字列の長さの範囲 (最大値と最小値)
- Kwalify ではパースしたあとの YAML ドキュメントを検証します。そのため、YAML ドキュメントだけでなく JSON ドキュメントも同じように検証できます。
- Kwalify ではスキーマを YAML フォーマットで記述します。そのため、アンカーとエイリアスを使って検証ルールの共有や再帰的な定義が簡単にできます。
- Kwalify ではスキーマ定義自身の検証も Kwalify で行います。スキーマ定義を検証するバリデータをメタバリデータといいます。
- Kwalify のバリデータは Ruby スクリプトで簡単に拡張できます。このとき、宣言的に書きやすいことは宣言的に、宣言的に書きにくいことは手続き的に検証できるよう設計されています。
Kwalify は決して高機能ではありませんし、RelaxNG のような数学的なバックグラウンドを持つわけでもありません。しかし普通に使う分には十分な機能を持っていますし、なによりスクリプトでいくらでも拡張できるため、大変便利です。
なお本当は XML のスキーマ (DTD, XML Schema, RelaxNG) と Kwalify とを比較してみたかったのですが、筆者の力不足でできませんでした。機会があればチャレンジしたいと思います。
著者について
名前:kwatch。三流プログラマー。もし世の中に「ソフトウェア構造計算書」なんてものが存在したらほとんどのプロジェクトでは偽造されるんやろなーと思ったが、バグを「仕様です」なんて言い切ってる時点で偽造してるのと変わらんやんと気づき、やや鬱。最近のお気に入りは「チャングム」。