あなたの Ruby コードを添削します 【第 1 回】 pukipa.rb
著者: 青木峰郎
- この連載について
- 今回のお題 〜pukipa.rb〜
- プログラムの意味の保証
- コーディングスタイルの改善
- 文単位の改善
- インターフェイスの改善
- メソッド単位の改善
- 添削終了!
- コードの「全体的なよさ」を計測する
- 速度比較
- おわりに
- 参考文献
- 著者について
- あなたの Ruby コードを添削します 連載一覧
この連載について
この連載では、投稿してもらった Ruby プログラムを様々な角度から添削してみようと思います。 添削基準は著者(今回は青木)の独断と偏見のみです。
きっかけになったのは
Open Source Conference 2005/Fall
で行われた「あなたの Ruby コードを添削します」というセミナーでした。
このセミナーは高橋征義さん・後藤裕蔵さん・青木の三人によって行われ、
好評をいただきました。

本来ならばそれで終わりのはずだったのですが、 その後行われた宴会の際に交わされたらしい、 こんな感じだったような気がする会話が命取りになってしまいました。
誰か「あの添削さあ、るびまでやったらいいんじゃない?」
青木「あー、それはいいかもねえやろうかー。10 月号でいいよね?」
昔の人は言いました。「酒は飲んでも飲まれるな」。 つくづく昔の人は無茶を言うものだと思う今日このごろです。
今回のお題 〜pukipa.rb〜
さて今回爼上にのせるのは、PukiWiki 文法のパーサ pukipa.rb (MIT ライセンス) です。 このプログラムは rails2u の gorou さんに提供していただきました。ありがとうございます。
PukiWiki というのは PHP 言語で実装された Wiki の一種で、 Wiki の中でも相当メジャーな部類に入ると思われます。
Wiki にはそれぞれ独自だったり独自ではなかったりする文法があり、 それを HTML に変換して表示しています。 pukipa.rb は PukiWiki の独自文法を HTML に変換するライブラリです。
PukiWiki 文法
まずはその独自文法について見ておきましょう。 pukipa.rb が扱う文法は本家 PukiWiki と比べるとかなり簡略化されていますが、基本は同じです。 すでに Wiki をあるていど知っているかた向けに一言で説明すると次のようになります。
- 見出しは「」「」「」「**」
- 箇条書きは「-」「–」「—」……
- 番号付き箇条書きは「+」「++」「+++」……
-
dl は「:dt dd」 - pre はスペースインデント
- ブロック引用は「>」
より詳しくは PukiWiki 本家の解説を参照してください。
pukipa.rb
では、オリジナルの pukipa.rb をお見せします。 わたしの添削結果を見る前に、みなさんならどこを変えるか考えてみるのもいいでしょう。
- pukipa.rb(別ページで表示)
プログラムの意味の保証
これから添削と同時にコードを変更していきますが、 そのときにコードの意味を変えないようにしなければなりません。 今回の事例で言えば、変換結果の HTML が変化しないようにしなければいけません。
コードの意味が変わっていないことを確認するには、テストを書くのがよいでしょう。 テストがあるからといって意味が変わっていないことが 100% 保証されるわけではありませんが、 思いがけず仕様を変えてしまう確率は下げられます。
今回は、test/unit を使ったテストを……書いたほうが格好いいのですが、 すべての文法を使ったテストデータが元のファイルについていましたので、 このデータの変換結果が Ruby の == で同じになることだけを確認しました。
ところで、今回のプログラムの出力は HTML ですから、 たとえテキストとして改行や空白が増えていても、HTML として構造が変化していなければ問題ないという考えかたもありえます。 そのような場合は htree を使ってチェックするのがよいでしょう。
コーディングスタイルの改善
まずはコードの意味に直接関係しないコーディングスタイルに関することから話を始めることにしましょう。
インデント
まずはインデントです。オリジナルのコードはタブ幅 を 2 と仮定してタブを使っていたようで、 タブ幅 が 8 のわたしの環境ではインデントが崩れてしまいました。 インデントに関しては各自の好みと論理があると思いますが、 わたしはタブが嫌いなのですべてスペースに展開しました。
また、インデント幅は元から 2 になっていましたので、 そのまま 2 に揃えました。 Ruby では 2 インデントが最も一般的ですので、 特に思うところがないなら 2 にしておくべきです。
括弧と空白
オリジナルのコードでは、メソッドを呼ぶとき、str_parse(str) のように空白がないスタイルと、Logger::new( $deferr ) のように空白を入れるスタイルが混在しています。 これは空白なしに統一しました。 経験的には、コードに目が慣れるほど空白が邪魔に感じられます。
カンマと空白
今度は逆に空白が少ない例です。オリジナルのコードは、list_parse(str,’ul’) のように、 カンマのあとに空白が入っていませんでした。 隙間がなさすぎるのもまた見にくいので、 「カンマの後には空白一つ」で統一しました。
また、演算子の左右にも空白がなかったので、 これも空白一つで統一しました。
ちなみに、わたしは普段コードに色をつけません。 ですから、つまったコードでも実は色がつけば多少は読みやすくなるのかもしれません。 ですが less の表示や grep の出力に色がつくわけではないので、 色が付く環境を前提にコーディングスタイルを決めるのは不適切だと考えています。
コメント
次にコメントです。
# dlのパーサ
def dl_parse(str)……という感じのコメントがほとんどのメソッドについていたのですが、dl_parse という名前のメソッドで dl をパースしていなかったら詐欺でしょう。 このコメントは意味がなさそうなので消すことにしました。
では、どういうコメントがついていたら有意義でしょうか。 例えば次のようなコメントは意味があるかもしれません。
# ":dt|dd\n:dt|dd\n..." という形式の文字列 str を
# パースして HTML の文字列配列を返す
def dl_parse(str)このコメントでは引数 str の形式と返り値を書いてみました。 わたしの好みからすると饒舌すぎるのですが、 少なくとも無駄にはならないコメントだと思います。
コーディングスタイルの統一
コーディングスタイルは人によってかなり違うと思います。 ここまでの話に賛成できないことも当然あるでしょう。 しかし、少なくとも、一つのプログラム内ではスタイルを統一すべきであるという点は同意していただけると思います。
文単位の改善
引き続き一般的な話を続けます。 今度は構文のレベルでプログラムを見ていきましょう。 キーワードは「Ruby らしさ」です。
リテラルへの式埋め込み
元コードの特徴として、リテラルへの式埋め込み(”#{…}”)を 執拗に避けていることが挙げられます。 例えば /lit#{code}eral/ で済むところを Regexp.new(“lit” + code + “eral”) とする、などです。
添削では、文字列および正規表現リテラルを書く場合、 式の埋め込みを積極的に使うように変更しました。 常に式埋め込みを使ったほうがよいとは言えませんが、 埋め込む式が単純なら、埋め込みを使ったほうがたいていは見やすくなります。 それに、式の埋め込みを使ったほうが、 最終的に得る値が文字列や正規表現であることがわかりやすくなります。
実際の例をひいて比較してみましょう。
添削前
@pagelist = Regexp.new('(?!<a.*?>.*?)((?:' + pagelist.join(')|(?:') + '))(?!.*?</a>)',Regexp::IGNORECASE )
添削後
@pagelist = /(?!<a.*?>.*?)((?:#{ pagelist.join(')|(?:') }))(?!.*?</a>)/iどうでしょうか。添削後でもやはり見にくいですが、 相対的に言えば見やすくなっていると思います。 また、@pagelist には正規表現が入るのだということもわかりやすいのではないでしょうか。
なお、コードの文脈まで含めて考えていくと、@pagelist はもっとわかりやすくできます。 これについてはまたあとで話しましょう。
unless と until
C や Java から Ruby 移行してきた人にありがちなのが、C/Java にもある構文ばかり使って Ruby 特有の構文を避けることです。 特に unless, until はなぜか嫌われているようです。
また、and や or を絶対に使わず && と || ばかり使うというケースも散見されます。 and/or と &&/|| では演算子の優先順位が違うので、 そのときどきで使い分けるのが適切です。
では個別の事例を見ていきましょう。
まず、
if !@scanner.eos?という式が見付かりました。これは、
if !@scanner.eos?
↓
if not @scanner.eos?
↓
unless @scanner.eos?と変形できます。「!@」と記号が連続すると非常に見にくいので、 この場合は unless か、せめて if not にするようお勧めします。
「while not」という表現もたくさん見付かりました。 これは単純に「until」に変換できます。
また、少しステップが増えますが、次の表現も変形できます。
if pagelist.size > 0まず pageslist.size > 0 は not pagesize.empty? に変換できます。 すると「if not」が現れるので、これも unless にできます。
if pagelist.size > 0
↓
if not pagelist.empty?
↓
unless pagelist.empty?ではなぜ if not よりも unless が、while not よりも until がよいのでしょうか。 その理由は、文を構成する要素数が減るからです。 わたしが「if not A」という式を見る場合、 まず if を見て、A を見て、それを not で反転します。つまり脳内操作は三つです。 しかし「unless A」の場合、unless を見て A を見れば終わりなので二つです。
別の表現をすると、わたしの感覚では「if not A」は「if (not A)」なのですが、 「unless A」は「(if not) A」と認識されます。 if は「〜という条件が当てはまるときだけ本体を実行してほしいんだけど」という意味であり、unless は「〜という条件が当てはまるときは実行しないでほしいんだけど」という意味です。 つまり if は「特殊な条件を指定する構文」であり、unless は「特殊な例外を排除する構文」なのです。
このあたりは説明するのが難しいのですが、 あるていど Ruby に慣れれば unless のほうが文を解釈する負担が少なくなると思います。
case
その次に気にかかったのがこういうコードです。
if str =~ /^ /
略
elsif str =~ /^>/
略
elsif str =~ /^-/
略
elsif str =~ /^\+/
略
elsif str =~ /^:/
略
else
略
endこの if 文はすべての条件式で変数 str を対象にマッチしています。 ですから次のように case 〜 when に書き直せます。
case str
when /^ /
略
when /^>/
略
when /^-/
略
when /^\+/
略
when /^:/
略
else
略
end念のため復習すると、case 文は、case の値(str)と when の値とを次々に「===」で比較して、 真を返した節を実行します。 つまりこの場合なら
/^ / === str
/^>/ === str
/^-/ === str
/^\+/ === str
/^:/ === strを次々に実行して、最初に真になった節を実行します。 そして Regexp#=== は Regexp#=~ と同じ意味ですから、 書き換えたあとの case 文が元の if 文と同じ意味であることがわかります。
見ためだけをとっても case を使った後者のほうが簡潔ですし、 意味的にも、case 文を使うと「これから str に関する比較をするぞ」 ということが明確になります。
到達しないはずのコード
if や case などで場合分けをしていると、 「コードの意味上、ここには絶対に到達しない」ケースが出てくることがあります。 到達しないのだから単に無視してもよいはずですが、 現実にはバグだのなんだので到達してしまう可能性があるわけです。 そこで次のようなコードが書かれることになります。
if @scanner.scan(/^\n/)
略
elsif ...
略
else
#ここにはこないはずなので・・・
raise PukipaParseError.new
end元のコードでは例外 PukipaParseError を投げていますが、これは変です。 到達しないコードに到達してしまうのはコードにバグがあるためであって、 解析中のテキストが間違っているせいではありません。 そこで次のように変更しました。
raise "must not happen"raise は例外クラスを省略すると RuntimeError を生成します。 これで PukipaParseError が必要なくなるので定義も消しました。 ちなみに「must not happen」というメッセージは確か『ソフトウェア作法』あたりで読んで以来使っています。
なぜ RuntimeError にするかと言うと、RuntimeError は StandardError の下位クラスではないので、 クラスを指定しない rescue では捕獲できないからです。 この例外はプログラムにバグがあることを報告するために投げているわけですから、そう簡単に捕まえられたくはないでしょう……
……と、セミナーで発言したのですが、その場で 「RuntimeError も StandardError の下位クラスだ」と間違いを指摘されてしまいました。 つまり、raise “must not happen” ではクラスを省略した rescue で捕獲されてしまいます。 そこで、新しい例外クラスを定義しなくても済む代替案をその場で募集したところ 「raise Exception, “must not happen” とする」という案が出されました。 多少字面が長いですが目的は果たせるのでとりあえずはこれでよしとします。
インターフェイスの改善
続いては pukipa.rb のインターフェイスを検討します。
クラス名とファイル名
まずクラス名から検証しましょう。このファイルには Pukipa(たぶん PukiWiki parser の略)というクラスが一つだけ定義されています。 Ruby ではファイル中のメインクラス名を downcase してファイル名にするのが標準的ですから、クラス名が Pukipa でファイル名が pukipa.rb ならば、 標準に沿っており適切です。
なお、Open Source Conference のセミナーでは「Pukipa という名前はどうなんだ」などなどとテキトーなツッコミを入れてみたのですが、あれは単にウケを狙っただけなので、 個人的には特に思うところはありません。 ありませんが、クラス名を変えておかないとテストなどが少々面倒になるので、 添削後のコードでは PukiWikiParser とクラス名を変えておきます。
元のインターフェイス
次にクラスのインターフェイスを見ます。 Pukipa クラスのインターフェイスはこうなっていました。
- Pukipa.new(plain)
- Pukipa#pagelist(pagelist, base_uri = ‘/’, suffix = ‘/’)
- Pukipa#to_html
まず Pukipa.new でソースコードを与え、Pukipa#pagelist で Wiki に存在するページ名を教え、Pukipa#to_html で HTML を生成します。
このインターフェイスでまず気になったのが pagelist メソッドの存在です。 このインターフェイスだと to_html メソッドを呼ぶ前に必ず pagelist メソッドを呼ばなければいけないのですが、 呼ぶほうが気をつけて順番通りに呼ばなければいけないという制約はどうにも不自由に感じられます。 いっそのこと一つにまとめてしまうわけにはいかないのでしょうか。 最終的には Pukipa クラスを使っているコードのほうを見ないとなんとも言えませんが、自分で Wiki を書いた経験から考えるに、 このメソッドを独立させる必然性はあまり感じられません。
また、initialize の中で Logger を生成しているのですが、logger の level やプログラム名などはパーサを使う側で設定したいことが多いので、logger は外から new に渡してもらうことにしました。 この変更により、pukipa.rb で logger を require する必要もなくなります。
そもそも、なんでパーサにロガーが必要なのかという疑問もあります。 しかも、のちのちコードを見ていくとわかりますが、 ロガーはデバッグにしか使われていません。 このクラスは独立して使えるのですから、 なにもロガーでデバッグ出力しなくてもいいように思えるのです。 が、添削に出すときに無理矢理構成を変えた可能性もあるかと考え、 添削後もいちおうロガーは使えるようにしておきました。
改善後のインターフェイス
以上の考察を経て、PukiWikiParser クラスのインターフェイスは次のようになりました。
- PukiWikiParser.new(logger)
- PukiWikiParser#to_html(src, page_names, base_uri = ‘/’, suffix = ‘/’)
pagelist メソッドはなくなり、 ページ名のリストは to_html メソッドにまとめて渡すようにしています。 ついでに引数 plain(ページのソースコード)も new から to_html に移動しました。これは logger を new に渡すようにした余波です。
ちょっと考えてみてください。 たぶん設定ファイルあたりに由来する logger はプロセス中は同じものが使えるはずです。 一方、ページのソースコードは CGI リクエストごとに変化するはずです。 つまり寿命も由来も違うわけで、両者を一緒に渡すよう要求してしまうと使いづらくなることうけあいです。ですから、new で要求するのは logger だけとし、CGI リクエストごとに変化するデータはすべて to_html で渡すことにしました。
ついでに、plain(たぶんプレーンテキストの plain)という変数名も src(ソースコードの source)に変えてみました。 PukiWiki のソースコードをプレーンテキストと呼んでいいかどうか 疑問に感じたからです。
可視性
珍しいことに、pukipa.rb では protected が使われています。 Ruby には public, private, protected の三種類の可視性がありますが、 通常使われるのは public と private のみです。 protected はほとんど使われていません。
public はいいとして、private と protected の違いはみなさん御存知でしょうか。 どちらを指定しても基本的にはオブジェクトの外からは呼べなくなるのですが、protected のメソッドは、同じクラスか、 その下位クラスのインスタンスに限っては外からでも呼ぶことができます。
しかし、pukipa.rb 全体を見ても protected である必要性は感じられませんでしたし、外から使われているわけでもありませんでした。 よってこれは単なる勘違いだろうと判断し、private に変えました。
メソッド単位の改善
ここからは実際のソースコードを追いながら、 メソッド単位でコードを検討していきます。
Pukipa#pagelist
まずは Pukipa#pagelist から見ていきましょう。
このメソッドは Wiki 内に存在するページ名をパーサに教えてあげるために用意されています。 ではなぜパーサが全てのページ名を知る必要があるかと言うと、 オートリンク機能のためなのです。
オートリンクとは、同じ Wiki 内に存在するページ名を書くと自動的にハイパーリンクになるという機能のことです。 例えば、「Ruby言語」というページがすでに存在するなら、 他のページのどこかに「Ruby言語」と書くだけでそれがリンクになるわけです。
元の pagelist メソッドでは次のようなコードでページ名にマッチする正規表現を作り、変換の準備をしていました。
# arrayでpagelistを渡す
# pagelistはwikiページ一覧
def pagelist(pagelist,base_uri = '/',suffix = '/')
@base_uri = base_uri
@pagelist_suffix = suffix
if pagelist.size > 0
#三文字以下はそもそも対象外
pagelist.reject!{|pn| pn.size <= 3 }
pagelist.map!{|pn| Regexp.escape(pn)}
@pagelist = Regexp.new('(?!<a.*?>.*?)((?:' + pagelist.join(')|(?:') + '))(?!.*?</a>)',Regexp::IGNORECASE )
end
end少し前に出てきた @pagelist の正体がこれです。 なお、ページが存在しないとき(pagelist.size > 0)のときは @pagelist が nil になるので、 この後、@pagelist を使うときに nil かどうかで分岐していました。
この @pagelist を作る部分をわたしが書き直したのが次のコードです。
def autolink_re
Regexp.union(* @page_names.reject {|name| name.size <= 3 })
endポイントごとに見ていきましょう。
まず、「正規表現を作ってインスタンス変数に格納する」メソッドを書くのではなく、 「正規表現を作る」メソッド autolink_re を書いて、その結果を使うようにしました。
次に、Regexp.new と Regexp.escape を自分で使うのではなく、 標準ライブラリのメソッド Regexp.union を使いました。 Regexp.union は Ruby 1.8.1 で追加されたメソッドで、 引数がすべて文字列の場合は以下と同じ意味です。
def Regexp.union(*strings)
return /(?!)/ if strings.empty?
new(strings.map {|s| escape(s) }.join('|'))
end例えば Regexp.union(‘aa’, ‘bb’, ‘cc’) は文字列 aa か bb か cc にマッチする正規表現を返します。
引数がゼロ個のとき(strings.empty?)にはどういう正規表現が返ってくるのでしょうか。 Regexp.union(‘aa’, ‘bb’) は aa か bb、Regexp.union(‘aa’) は aa ……と順番に考えてみると、 引数がゼロ個のときは「どんな文字列にもマッチしない」 パターンが適切であるとわかります。それが /(?!)/ です。
Regexp.union は常に正規表現を返してきますから、nil かどうかによる場合分けをする必要もなくなります。
このように、標準のメソッドをとことん使いたおしていけばコードを圧倒的に簡潔にできるのです。 String・Regexp・Array・Hash・Enumerable あたりだけで十分ですから、リファレンスマニュアルは熟読しておきましょう。
Pukipa#to_html, #block_parse
ここからは HTML への変換のコードです。
def to_html
plain = @plain.gsub(/\r?\n/,"\n").chomp + "\n"
result = []
block_regex = /^([:\-+> ]).*\n(?:(?:\1.*\n)+)?/
@scanner = StringScanner.new( plain )
while !@scanner.eos?
if @scanner.scan(/^\n/)
#空行
elsif @scanner.scan(/^----.*?\n/)
result << '<hr />'
elsif @scanner.scan(block_regex)
result << block_parse(@scanner.matched)
elsif @scanner.scan(/^\*.*?\n/)
result << h_parse(@scanner.matched)
elsif @scanner.scan(/^([^*:\-+> \n].+?\n){1,}/)
result << block_parse(@scanner.matched)
elsif @scanner.scan(/(.*)/)
result << block_parse(@scanner.matched)
else
#ここにはこないはずなので・・・
raise PukipaParseError.new
end
end
result.join("\n")
endこのメソッドではソースコードを文法の種類ごとに分割しています。 箇条書きや dl などの複数行に渡るブロックの場合はその複数行をまとめて読み、block_parse であらためて処理します。 h や hr のように一行で済む場合はメソッド内で処理してしまいます。
まず考えたのは、ul や dl のように複数行に渡るブロックを to_html と block_parse の二ヶ所に分けて処理するのは無駄ではないかということです。 to_html では正規表現を使ってブロックに分割しているのですから、 ここで ul や dl の判定も同時にやってしまってもコードは複雑にはなりません。
次に、StringScanner は必要ないのではないかということです。 StringScanner(strscan)はわたしの作なので使ってもらえるのは嬉しいのですが、この状況ではあまり使う価値はありません。 Wiki の文法というのは行単位ですから、無理に文字列のまま処理するよりも、まず行ごとの配列にしてしまい、配列を相手にしたほうが楽なのです。 実際、block_parse では String#each_line を使って行ごとに処理しています。 最初から行の配列にしておけばそんな苦労はいりません。
ただ、行の配列になると複数行に渡る ul や dl のブロックを取り出すのがちょっと厄介になります。 そこで行配列からブロックを取り出すためのメソッド take_block を定義しました。
def take_block(lines, marker)
buf = []
until lines.empty?
break unless marker =~ lines.first
buf.push lines.shift.sub(marker, '')
end
buf
endtake_block は文字列配列 lines の先頭から正規表現 marker にマッチする行をすべて取って配列で返します。 そのときついでに marker にマッチする部分は削ってしまいます。
Pukipa#h_parse
では *_parse メソッドを順々に見ていきます。 まずは見出し(h1, h2…)を処理するコードからです。 このメソッドは “** 見出し” のような文字列を “<h3>見出し</h3>” と変換します。
def h_parse(str)
str.chomp!
h_regexs = {
'*' => 'h' + @h_start_level.to_s,
'**' => 'h' + (@h_start_level + 1).to_s,
'***' => 'h' + (@h_start_level + 2).to_s,
'****' => 'h' + (@h_start_level + 3).to_s,
}
h_regexs.each do |tmp_regex,prefix|
regex = Regexp.new('^' + Regexp.escape(tmp_regex) + '([^*])')
if str =~ regex
str.gsub!(regex,"\\1").gsub!(/^\s+/,'')
str = "<%s>%s</%s>" % [prefix,str_parse(str),prefix]
break
end
end
@log.debug "inline:\n%s" % str
str
endこのメソッドの不幸は、h_regexs のデータ構造でしくじってしまったことです。 例えば次のような構造にしておけばずっと簡単になったはずなのです。
h_table = [
[/^\*\*\*\*/, @h_start_level + 3],
[/^\*\*\*/, @h_start_level + 2],
[/^\*\*/, @h_start_level + 1],
[/^\*/, @h_start_level + 0]
]Enumerable#detect(#find)と組み合わせればさらに美しく書けます。
re, level = *h_table.detect {|re, *| re =~ str }
str.sub!(re, '').gsub!(/^\s+/, '')
@log.debug "inline:\n%s" % str
"<h%d>%s</h%d>" % [level, str_parse(str), level]このように、見ためもコードの流れもスッキリしました。
さらに、わたしならテーブルを作ること自体をやめて次のように書きます。
def parse_h(line)
@logger.debug "h: #{line.inspect}"
level = @h_start_level + (line.slice(/\A\*{1,4}/).length - 1)
content = line.sub(/\A\*+\s+/, '')
"<h#{level}>#{parse_inline(content)}</h#{level}>"
endまず String#slice で正規表現にマッチした部分を取り出し、h のレベルを計算します。 次に String#sub で行先頭のアスタリスクを削ります。 最後に h エレメントを作ります。 一行一動作にまとまり、わかりやすくなったでしょう。
多くのメソッドを使うことの是非
h_parse についてはセミナー当日、 「元のコードのほうが自明でわかりやすいと思う」 という意見が出されました。より抽象的な主旨としては、 「(青木しか使ってないような String#slice より) みんなが知っているメソッドだけを使ったコードのほうがわかりやすいのではないか」 という提起です。
わたしも、この提起の主旨には賛成します。 つまり誰も知らないようなメソッドやライブラリを使ってもあまりわかりやすくはならないだろうと思います。
しかし、このケースに関してはわたしのコードのほうに優位性があると主張します。 String#slice(regexp) は確かに入門書でいきなり使われるメソッドではないでしょうが(わたしは書くべきだと思いますが)、Ruby 1.6 あたりから標準ライブラリに入っている古いメソッドです。 これを「誰も知らない」と言われてしまうのでは Ruby のメソッドの大部分は使えなくなるでしょう。
また、「もっとメジャーなメソッドの組み合わせで書けるから必要ない」 という意見に対しては、まったく少しも全然微塵も賛成できません。 プログラミング言語の目的はプログラムを人間に理解しやすくすることです。 プリミティブな操作を組み合わせた「結果として」 X という操作を実行できる場合、 われわれが知りたいのは「結果として X になる」ということなのです。 それを知るために、わざわざプリミティブな操作をすべて追っていかなければならないというのは理不尽極まりありません。
したがって、わたしの結論はこうです。 「ちょうど求める働きをするメソッドがあるのなら、どんどん使うべきである。 少なくともよく知られているメソッドに関しては」。
Pukipa#dl_parse
続いてはリスト関係をスキップして dl_parse に行きます。
def dl_parse(str)
regex = /^:/
regex2 = /(.*?)\|(.*)/
str = str.map{|s| s.gsub(regex,'')}.join
result = []
result << "<dl>"
tmp = []
str.each_line do |s|
s.chomp!
m = regex2.match(s)
if m
result << "<dt>" + str_parse(m[1]) + "</dt>"
result << "<dd>" + str_parse(m[2]) + "</dd>"
else
result << "<dt>" + str_parse(s) + "</dt>"
end
end
result << "</dl>"
result.join "\n"
endすぐに気付いたのが、ローカル変数 regex, regex2 の意味がないということです。 どちらも一回ずつしか使われていませんから、直接埋め込んでしまえば十分でしょう。
なお、セミナーの当日に会場で「一回しか使われていないからといってリテラルを埋め込んでしまったらマジックナンバーのようにならないか」という質問がありました。 わたしの答えはこうです。「正規表現はマジックナンバーではない」。 マジックナンバーとは、それ自体では意味をなさない、 本質的には他の何であっても構わない数値のことです。 しかし正規表現はそれ自体で十分に意味が限定されますから、 マジックナンバーと同列に考えるべきではありません。
とは言えもちろん、正規表現が非常に複雑なときにはすぐに意味がとれませんから、 名前を付ける価値はあります。しかしそれはマジックナンバーというより、 複雑な手続きを関数としてくくりだす操作にたとえられるべきです。 一つの正規表現が複数回使われる場合も同様です。
また、マジックナンバーをマジックナンバーでなくするためには適切な名前を付ける必要があります。 ひるがえって「regex」「regex2」という変数名はどうでしょうか。 これでは型以外の情報をすべて捨ててしまっており、 むしろ情報量が低下しています。せっかく名前を付けるのなら、 例えば dl_marker_re と dl_body_re のような名前にすべきでしょう。
ところで、そんな話をすべて無にしかねないのですが、 コードの意味をよくよく考えると regex2 はそもそも必要ありません。 また、改善後のコードでは引数の文字列からすでに「:」がなくなっているので、regex も必要ありません。最終的なコードはこうなりました。
def parse_dl(lines)
@logger.debug "dl: #{lines.inspect}"
buf = ["<dl>"]
lines.each do |line|
dt, dd = *line.split('|', 2)
buf.push "<dt>#{parse_inline(dt)}</dt>"
buf.push "<dd>#{parse_inline(dd)}</dd>" if dd
end
buf.push "</dl>"
buf
endString#split を使うことでコードが全体的にコンパクトになり、dt を生成するコードを二行書く必要もなくなりました。 文字列リテラルの式埋め込みも効果的に使われていますね。
Pukipa#str_parse
次はテキストのパーサ、str_parse です。 このメソッドの仕事は主にハイパーリンクを張ることですが、HTML の特殊文字のエスケープも同時に行っています。
def str_parse(str)
#URIへの自動リンクは一番最初にやる
uri_regex = Regexp.new('(?!\[\[.*?)(' + URI.regexp('http').source + ')(?!.*?\]\])',Regexp::EXTENDED)
str.gsub!(uri_regex) do |match|
uri = $1.dup
re = match
re = '[[%s:%s]]' % [uri,uri] if not uri =~ /\]\]$/
re
end
str = escapeHTML(str)
#リンク
str.gsub!(/\[\[(.+?):\s*(https?:\/\/.+?)\s*\]\]/) do
name = $1.dup
uri = $2.dup
'<a class="outlink" href="%s">%s</a>' % [uri,name]
end
#ページにリンク
if @pagelist
str.gsub!(@pagelist) do
s = $1.dup
'<a class="pagelink" href="%s%s%s">%s</a>' % [@base_uri,escape(s),@pagelist_suffix,s]
end
end
str
endこのメソッドの最大の問題は、gsub を何度も使うというデザインです。 この方法を選んだために、最初のほうの段階で文字列に HTML のタグが入ってしまい、 あとになるほど処理が(正規表現が)どんどんややこしくなってしまいます。
この問題を解決するには、三つの gsub と escapeHTML を一つの gsub にまとめなければいけません。 すると当然正規表現も一つしか使えなくなるので、
- HTML の特殊文字
- URL
- ブラケットリンク([[ …. ]]を使ったハイパーリンクの表記法)
- Wiki 内に存在するページ名
の四つすべてにマッチする正規表現を使う必要があります。 とにかく改善後のコードを見てもらいましょう。
def parse_inline(str)
@inline_re ||= %r<
([&<>"]) # $1: HTML escape characters
| \[\[(.+?):\s*(https?://\S+)\s*\]\] # $2: label, $3: URI
| (#{autolink_re()}) # $4: Page name autolink
| (#{URI.regexp('http')}) # $5...: URI autolink
>x
str.gsub(@inline_re) {
case
when htmlchar = $1 then escape(htmlchar)
when bracket = $2 then a_href($3, bracket, 'outlink')
when pagename = $4 then a_href(page_uri(pagename), pagename, 'pagelink')
when uri = $5 then a_href(uri, uri, 'outlink')
else
raise 'must not happen'
end
}
end最初の数行で正規表現を一つだけ作っています。 %r を使った正規表現リテラル(デリミタ変更)と x オプション(正規表現内の空白類およびコメントを削除)を同時に使っているので、 かなり理解しにくいでしょう。正規表現としては以下と同じです。
/([&<>"])|\[\[(.+?):\s*(https?://\S+)\s*\]\]|(#{autolink_re()})|(#{URI.regexp('http')})/この正規表現の意味は、コード中のコメントを見てもらえばだいたいわかるでしょう。 $1 が HTML の特殊文字、$2, $3 がブラケットリンク、$4 がページ名オートリンク、$5 が URL オートリンクです。 それを gsub に使い、どの $n が存在するかをチェックすることで、 四つのうちどのパターンにマッチしたのかを確かめます。
それから、case のあとに式がない case 文は Ruby 1.8 から導入された新文法です。 if 〜 elsif 〜 else と全く同じ意味で、最初に真になった when 節が実行されます。 Lisp を知っている人には「cond です」の一言で通じるでしょう。
Pukipa#escapeHTML, #escape
最後のメソッドは、これまでに何度か登場した escapeHTML と escape です。 escapeHTML は HTML で特別な意味を持つ「<」や「>」を実体参照に置き換え、escape は URL の特殊文字をエスケープします。
def escapeHTML(string)
string.gsub(/&/n, '&').gsub(/\"/n, '"').gsub(/>/n, '>').gsub(/</n, '<')
end
def escape(string)
string.gsub(/([^ a-zA-Z0-9_.-]+)/n) do
'%' + $1.unpack('H2' * $1.size).join('%').upcase
end.tr(' ', '+')
end実はこのメソッドはどちらも標準添付ライブラリ cgi.rb とまったく同じ内容です。 おそらく cgi.rb からコピー & ペーストしたものと思われます。 添削的には cgi.rb を require して CGI.escapeHTML と CGI.escape を使うのがよいのでしょうが、 いろいろと気に食わなかったのでモジュールとして書き直しました。
module HTMLUtils
ESC = {
'&' => '&',
'"' => '"',
'<' => '<',
'>' => '>'
}
def escape(str)
table = ESC # optimize
str.gsub(/[&"<>]/n) {|s| table[s] }
end
def urlencode(str)
str.gsub(/[^\w\.\-]/n) {|ch| sprintf('%%%02X', ch[0]) }
end
endちなみに、気に食わなかったところは三つあります。
- escapeHTML が gsub を何回も呼んでいるのが嫌
- なんで escape_html じゃないんだ
- URL なら escape じゃなくて encode だろ!
なお、このコードは新規に書き起こしたわけではなく、 ローカルの自作ライブラリ置き場からみつくろって持ってきただけです。 HTMLUtils.escape は CGI.escapeHTML に比較してエスケープする文字列が少ないときに速いという利点があります。
添削終了!
以上で添削は終わりです。 今回の改善におけるポイントをまとめておきましょう。
- コーディングスタイルは統一する
- unless, until のような Ruby 独特の構文も好き嫌いなく使う
- データ構造はよくよく考える
- 標準ライブラリのメソッドを活用する
- 正規表現を使う前に別のメソッドを検討してみる
- 正規表現を使うなら最大限まで意味を持たせる
最後に添削前・添削後のソースコードを置いておきますので、 見比べてみてください。
- pukipa.rb(別ページで表示)
- pukiwikiparser.rb(別ページで表示)
- osc2005-ruby.tar.gz(まとめてダウンロード)
コードの「全体的なよさ」を計測する
さて、ここまでさまざまな角度からコードを「改善」してきました。 しかし、それをすべて合わせたときに全体としてどうなっているのかについてはまだ検討されていません。 この節ではプログラムの全体的な「よさ」について、 あるていど定量的な計測を試みます。
コード量
まず、コード量はどうでしょうか。 古典的なコード量計測の手段として、行数を比較してみましょう。 行数が減ればいいわけではないのは当然ですが、 だからと言って一切の比較を拒否するのは行きすぎです。 わかりやすさ(複雑さ)が同じくらいのコード同士で比較するなら、 行数・文字数の少ないほうがよいに決まっています。
~/c/osc2005 % wc pukipa.rb pukiwikiparser.rb
203 505 5110 pukipa.rb
165 401 4161 pukiwikiparser.rbこのように、コード行数は 203 行 → 165 行と約 20% 削減できました。 文字数もほぼ同様の割合で減っています。 コメントだけの行や空行も消しているのでそのまま受け取ることはできませんが、 これだけ違えば十分効果が出ていると言えるでしょう。
その内訳を見ると、h_parse, block_parse, list_parse の三つが行数削減に大きく響いているようです。 特に to_html と block_parse を一本化したことが行数削減につながっています。
メソッドの行数の分布
ファイル全体の行数を比較しただけではコードが読みやすくなったかどうかはわかりません。 同じ 1000 行でも、50 行のメソッドが 20 個の場合と main メソッドが一つで 1000 行の場合とでは、 恐らく前者のほうがずっと読みやすいはずです。
そこで今度はメソッドの行数の傾向を比較してみましょう。 次のグラフは、メソッドを行数ごとにプロットしたものです。 例えば pukipa.rb の場合、3 行のメソッドが一つ、5 行のメソッドが一つ……という具合に読みます。
~/c/osc2005 % method-lines-distribution puki*.rb
pukipa.rb pukiwikiparser.rb
1: 1:
2: 2:
3: * 3: ****
4: 4: ***
5: * 5: **
6: 6: **
7: 7:
8: 8: *
9: 9:
10: * 10:
11: 11: *
12: * 12:
13: 13:
14: 14:
15: 15: *
16: 16:
17: 17:
18: 18: *
19: 19:
20: ** 20:
21: 21:
22: * 22:
23: 23:
24: 24:
25: * 25:
26: 26:
27: 27:
28: 28:
29: * 29:
30: 30:
31: 31:
32: 32:
33: 33:
34: * 34:
35: 35: *このグラフによると、添削後は長いメソッドが相対的に減り、 短いメソッドが増えていることがわかります。 一般的に言ってこれはプログラムが「よい」構造に変化したことを示しています。
※ メソッドの行数の分布を見るという方法は、 藤原博文『C プログラミング診断室』を参考にしました。
メソッド間の構造
ですがコードがわかりやすくなっているのかどうか、まだまだ疑えます。 メソッドが全体的に短くなっても、 メソッド同士が複雑怪奇な構造で呼び合っていたら、 理解するのは非常に難しいはずです。
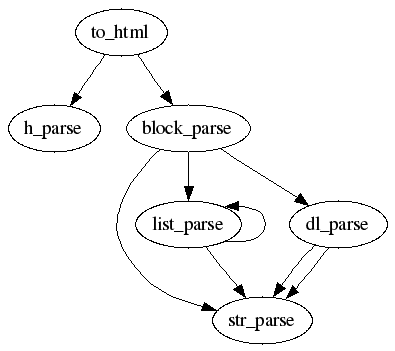
そこで今回はコールグラフを使ってメソッド間の構造を解析します。 コールグラフというのは手続き(メソッド)の呼び出し関係を図にしたものです。 ソースコード上での呼び出し関係を表現したスタティックコールグラフ(static call graph)と、 実行時に呼び出された手続きだけを表現したダイナミックコールグラフ(dynamic call graph)があります。 今回お見せするのはスタティックコールグラフです。
以下に改善前・改善後のプログラムそれぞれのスタティックコールグラフを示します。
改善前:
改善後:
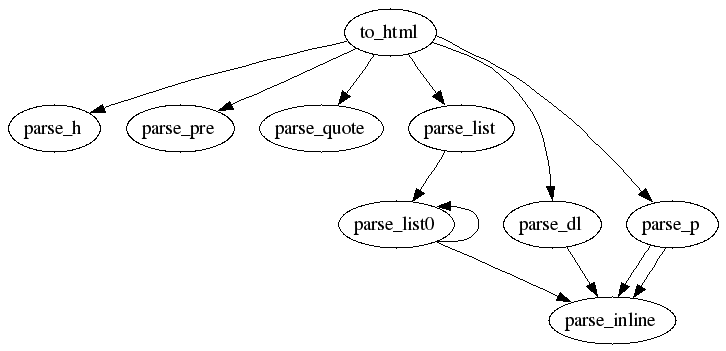
いかがでしょうか。 改善後のコールグラフは要素数(メソッド数)こそ増えていますが、 わかりづらくなったとは感じられないと思います。 つまり、メソッド同士の関係は複雑化していないということです。
速度比較
コードはわかりやすくなったけど速度は落ちた…… というのでは、あまり嬉しくありません。 最後は速度を比較することにしましょう。
ベンチマークの結果
以下に添削前と添削後の速度比較を示します。 ベンチマークのコードでは、 すべての文法を網羅したテストデータを 1000 回パースする時間を比較しました。 単位は秒です。
original …… 添削前
aamine …… 添削後(青木版) ---- Ruby 1.8.2 --------------------------------------
user system total real
original 12.770000 0.030000 12.800000 ( 12.905975)
aamine 2.240000 0.000000 2.240000 ( 2.274815) ---- Ruby 1.9 2005-08-29 -----------------------------
user system total real
original 25.040000 0.040000 25.080000 ( 25.308324)
aamine 2.120000 0.000000 2.120000 ( 2.138534)なんと、書き換えによって 6 〜 12 倍の高速化を達成できました。
原因の追究 (1) ガベージコレクション
しかし、高速になったこと自体はよいのですが、 いったいなぜこんなに速度差がついたのでしょうか。 無駄な計算はチマチマと省きましたが、 これほど効果が出るようなことはやっていないはずです。 それどころか、破壊的メソッドを意図的に排除したので、 生成されるオブジェクトの数はむしろ増えているはずです。
では、なぜ青木版のコードはこんなに速くなったのでしょうか。
まず考えたのは、青木版のコードが Ruby 1.8/1.9 の特性、 特にガベージコレクションの特性にうまくはまっているせいではないか、 ということです。ガベージコレクションが実行時間に占める割合は意外なほど大きく、プログラムがガベージコレクタの特性に合っているかどうかによって実行時間が秒単位で変わることもあるからです。
しかし、この推測はすぐに否定されました。 GC.disable でガベージコレクションを停止しても、 実行時間がほとんど変わらなかったからです。
原因の追究 (2) プロファイリング
となると、やはりコード自体の実行時間に差があると考えるしかありません。 いくつか推測もしてみましたが、 こういう場合はやはり現物でプロファイリングをとるのが王道でしょう。 Ruby でプロファイルをとるには、ruby コマンドに -r profile とオプションを付けてプログラムを実行します。 するとプログラム終了後、標準エラー出力にプロファイルが出力されます。 以下にオリジナル版のプロファイルを示します。
% cumulative self self total
time seconds seconds calls ms/call ms/call name
22.22 0.44 0.44 580 0.76 0.88 URI.regexp
12.12 0.68 0.24 1619 0.15 0.15 Regexp#initialize
11.62 0.91 0.23 20 11.50 95.00 Pukipa#to_html
8.59 1.08 0.17 580 0.29 1.83 Pukipa#str_parse
6.06 1.20 0.12 240 0.50 3.21 Pukipa#h_parse
5.56 1.31 0.11 240 0.46 2.50 Hash#each
以下略この出力を見ると URI.regexp(URI にマッチする正規表現を返すメソッド)で時間がかかっているようです。また次の Regexp#initialize も正規表現を生成するメソッドですから、両方合わせると、pukipa.rb は実行時間の 34% を正規表現の生成だけに費しているということになります。
改善策
URI.regexp は str_parse の中で次のように使われています。
uri_regex = Regexp.new('(?!\[\[.*?)(' + URI.regexp('http').source + ')(?!.*?\]\])',Regexp::EXTENDED)問題は、str_parse が非常にたくさん呼ばれるメソッドだということです。 しかも、実は uri_regex は毎回同じ値になります。 つまり uri_regex を作るのはプロセスにつき一回でいいはずなのです。 何度も呼ばれる str_parse 内で毎回作りなおす必要はありません。 そこで次のように、uri_regex の値をキャッシュするようにしてみました。
uri_regex = uri_re()
:
:
def uri_re
@uri_re ||= /(?!\[\[.*?)(#{URI.regexp('http')})(?!.*?\]\])/x
endすると、この変更を加えるだけで速度が一気に 10 倍近くになり、 添削後とほぼ同じ速度になりました。
速度差がこの一行だけで決定していたという事実はちょっと悲しいものです。 しかし少なくとも添削後のコードが遅くなっているわけではないことは明らかになりましたから、これでよしとしましょう。
おわりに
今回は PukiWiki 文法のパーサ pukipa.rb をテーマに、Ruby プログラムの改善についてお話ししました。 テーマがかなり普遍的なテキスト処理でしたから、広く応用できると思います。 みなさんもこの機会に自分のコードを見直してみてはいかがでしょうか。
プログラム募集
(酒の)勢いだけで始まったこの企画ですが、どうやら連載になる模様です。 が、添削するプログラムのストックがあまりないので、この場でプログラムを募集します。 添削してほしいプログラムがあるかたはるびま編集部まで御応募ください。 今回のプログラムは正味 200 行程度でしたが、 できればそれ以下の分量を希望します。
次回予告
連載の第 2 回は(たぶん)(きっと)(運がよければ)次号掲載予定です。 何を添削するかは全然まったく決まっておりませんが、 コード自体をいじるときの基本的な話は今回すべてやってしまったので、 次回はちょっと違う視点からお話ししたいと考えています。
参考文献



著者について
青木峰郎(あおき・みねろう)
ふつうの文系プログラマ。 本業はいちおう哲学ということになっている。 主著『Ruby ソースコード完全解説』 『ふつうの Linux プログラミング』 『Ruby レシピブック』。