あなたの Ruby コードを添削します 【第 3 回】 dbf.rb
著者:青木峰郎
はじめに
冬です。移動性高気圧の曲線はいやらしすぎます。
しかし今回は参りましたね。東京のくせに路地に雪が積もりやがってます。 だいたいあれですよ、武蔵野線は止まるの早すぎですよ。 弱すぎですよ。脆弱すぎですよ。too weak. まあ、武蔵野線なんて乗らないからどうでもいいけどね。
で も ね
車体が同じオレンジ色でも中央線が止まる理由は雪じゃないのよアハハン。
今回のテーマ
そんな和やかな枕をはさみつつ、流れるように今回のテーマ説明に入りたいと思います。 今回のお題は yrock さんに提供していただいた dbf.rb です。 dbf.rb は昔なつかしい dBASE というデータベースのファイルを読み書きするライブラリです。
これまでと同じく、 今回もシリアライズとパースが重要ポイントです。 これまでに扱ったポイントが多く登場してくるので、 この機会に過去の記事を復習してみるのもよいでしょう。
ソースコード
今回もまず添削前のソースコードを示します。
- dbf.rb (オンラインで表示)
- dbfrecomb.rb (オンラインで表示)
- CodeReview-0013.tar.gz (まとめてダウンロード)
dbf.rb がライブラリで、dbfrecomb.rb はそのサンプルコードです。 dbf.rb は Ruby ライセンスですので、 添削後のコードも Ruby ライセンスで公開します。
難易度について
ところで、前回の記事について某所で 「青木のコードは小難かしくてわからん」という意見をいただきました。 今回はそれを踏まえてより平易なコードを心がけ……るとでも思ったらまるっと大間違いだ! 今回は前回よりもさらにリフレクションを活用してみました。 がんばって読んでください。
コーディングスタイルの改善
今回も最初はアプリケーション特有でない話から始めましょう。
コメント
例えばこんなコメントがありました。
@headerlen = 0 # ヘッダ長
@recordlen = 0 # レコード長@headerlen が header の length だということくらいはプログラマなら誰でもわかります。 どうせなら、長さの単位は何か、どこからどこまでの長さなのか、 などの情報が欲しいところです。
あるいはこんなコメントがありました。
@dbfeof = FALSE #EOF
@dbfbof = FALSE #BOFこれも情報が少なすぎます。 EOF が end of file だろうってのはわかりますが、 BOF が何の略なのかわかりません。 コードを読んでみたら beginning of file の略だということがわかりました。
また、この二つの変数には false が代入されているところを見ると真偽値をとるようです。 つまり @dbfeof は「EOF の位置」でも「EOF のマーク」でもなく 「EOF に達したかどうか」を表している、のだろうなあ〜……と想像できます。 しかし想像は間違っている場合があるので、 できればそういうことをコメントに書いてほしいわけです。 例えば次のように書いておいたらどうでしょうか。
@eofp = false # true if @f is at EOF (End Of File).
@bofp = false # true if @f is at BOF (Beginning Of File).こんなコメントもありました。
def writerecord
# 1バイト空白を出力 (dbfファイル仕様の削除マーク)
@fp.write(" ")このコメントを見たら普通は 「空白が削除マークなんだなあ」と思うのではないでしょうか。 しかし writerecord というメソッド名からすると、 別にレコードを削除しているわけではなさそうです。 実にミスリーディングです。
仕様を見てわかったのですが、 実はこのバイトが空白の場合はレコードは「生きて」おり、 アスタリスク (‘*’) の場合はレコードが削除されている (無効になる、死ぬ) のです。 上記のコメントは「削除マーク」ではなく「削除されているかどうかを示すバイト」 とでも書けばよかったのでしょうね。
さらにこんなコメントまでありました。
end # while count < (@fields.numfields) doこんなコメントを付けたくなるのは、 コードが無駄に長く、ネストが深いからです。 コードが整理されていれば対応など一目でわかります。 コメントで逃げるのはやめましょう。
ちなみに、よいコメントもありました。 例えば次のようなコメントは有用だと思います。
@headerset = FALSE # ファイルにヘッダ部が書き込まれているか
@currentrecno = -1 # 0から始まるレコード番号
@numrecords = 0 # 1から始まるレコード数0 から始まるレコード番号に -1 を入れて異常状態を知らせる手法は いまいちだと思いますが、それが明示してあること自体は有意義でした。
識別子
Ruby の標準的なコーディングスタイルでは、 それぞれの識別子に次のようなスタイルを使います。
- variable_name
- method_name
- ModuleName
- ClassName
- ConstName
- filename
また、これまでも何度か扱っているように、 ファイル名はそのファイルに記述されている主要クラスを downcase して決定します。
さて dbf.rb では variablename のように アンダースコアを使わないスタイルが多用されていました。 これは気に食わないので、すべてアンダースコアを付けることにしました。 例えば movefirst は move_first に、movenext は move_next にします。
ただ、この修正後のメソッドも意味を考えるといまいち気に入りませんでした。 最終的にはそれぞれ first と next に単純化しています。
変数名
スタイルとしてではなく、意味的に不適切な変数名も目に付きました。 代表例は @fp (file pointer) です。 この変数名は他の Ruby プログラムでもときどき目にしますが、まったく不適切だと思います。 なぜなら Ruby 言語に pointer という概念は存在しないからです。 C 言語の命名慣習をそのまま持ち込むのはやめましょう。
では File オブジェクトの変数名としては何が適切でしょうか。 個人的には、f, input, output を多用しています。 file も使うことがありますが、 これだとパスのようにも見えて紛らわしいことがあるのであまり積極的には使いません。 インスタンス変数に使う場合、さすがに @f は短すぎるような気もするのですが、 いまいち他に思いつかないときは @f で済ますこともあります。 今回も @f を使いました。
メソッド名
メソッド名が冗長なのも気になりました。 例えば DBFfield#fieldname というメソッドがあります。 このメソッドを実際に使うと次のようになってしまいます。
field.fieldnamedbf.field('rainfall').fieldname明らかに、field が冗長です。 ふつう、レシーバを見ればクラスは想像がつくので、 レシーバに関する情報をメソッド名に入れると冗長になってしまいます。 DBFfield#name で十分でしょう。
クラス名
次にクラス名です。 dbf.rb のクラスは DBFheader, DBFfield, DBFrecordset という名前でした。 すべてのクラス名に「DBF」がついているのは冗長です。 「DBF」をくくりだしてモジュールを階層化しましょう。 つまり次のようになります。
module DBF
class Header
……
end
class Field
……
end
class RecordSet
……
end
endこれで各クラスが DBF というライブラリに属していることが明確になりますし、 ライブラリ内部では「Header」や「Field」のような 簡潔な名前でクラスを参照できるようになります。 また、ファイル名の dbf.rb とモジュール名 DBF の downcase が一致したので、 ファイル名も標準コーディングスタイルに合ったものになりました。
then と do
次に then と do について。
if @fp != nil thenwhile count < numfields dothen や do をつけるかどうか、 なんてのはほとんど趣味の領域なのでどちらでも構いません。 構いませんが、個人的には省略しています。 最初のころは絶対に省略しないようにしていたのですが、 then があると後置 if に変更するのが面倒なのでだんだん付けなくなりました。
ちなみに最近はこんな書きかたをするときもあります。
if @linkmap[id]
then a_href(escape(sprintf(@linkmap[id], vary)), escape(idvary))
else escape(idvary)
endこういう書きかたをするのは、then/else とも一文で済み、 if 式全体の値を使う場合です。 シェルスクリプトか何かで見て使うようになったのが始まりです。
require
ライブラリを require するときは拡張子を取るのが原則です。
require "dbf.rb"は
require "dbf"にしましょう。
require するのは dbf という機能が使いたいからであって、 それが Ruby プログラムであるか拡張ライブラリであるかなんてのは どうでもいいことです。そしてどうでもいいことなら書くべきではありません。
ただし例外もあります。例えば xxx.rb と xxx.so の両方があるときです。 このようなときは拡張子を省略すると xxx.rb が優先されるので、 xxx.so をロードしなければならない場面では require “xxx.so” と明示しなければいけません。
TRUE/FALSE
@dbfeof = FALSE #EOF
@dbfbof = FALSE #BOF次に大文字の TRUE と FALSE です。 大文字の (定数の) TRUE、FALSE は捨てて、true と false を使いましょう。
そもそも大文字の TRUE、FALSE なんてものがあったことを知らない人もいるかもしれません。 大昔の Ruby には true、false の文法が存在せず、 定数の TRUE, FALSE に現在で言う true と false がセットされていました。 しかし、たしか Ruby 1.1 になるあたりで true、false が新設されて、 それ以降は大文字の TRUE、FALSE は使うべきではないとされています。 いつなくなるか知れたものではありませんから、 大文字の TRUE、FALSE は問答無用で捨てるべきです。
というか、TRUE、FALSE のように古い記法がいったいどこから伝わったのか謎です。 昔のものがそのまま残っているユーザガイドでしょうか。 あれも早いところ書き直さないとまずいですね。
コードの局所的な改善
続いてはコードの意味にも立ち入ってリファクタリングしていきましょう。
マジックナンバー
マジックナンバーには名前をつけろというのは古典的な話です。 しかし次のように書いてあると意外と気がつかないものでしょうか。
# ファイルの終端マーク (Chr(26)、&H1A、&O32) を書き込む
@f.seek(0 + @headerlen + @recordlen * @numrecords, File::SEEK_SET)
@f.write("\x1a")“\x1a” がマジックナンバーです。 コメントをつけたからよいというものではありません。 まず名前をつけて、コメントをつけるなら名前のほうにつけるべきです。
EOF = "\x1a" # EOF (End Of File) mark of dBASE
……
@f.seek @headerlen + @recordlen * @numrecords, File::SEEK_SET
@f.write EOFさらに、EOF を書き込むコードを単独のメソッドに分割してもよいでしょう。
def put_eof
@f.seek @headerlen + @recordlen * @numrecords, File::SEEK_SET
@f.write EOF
endこれなら最初のコメントとほぼ同じ情報がコード上に表現されています。
nil、false との比較
ああこれは Ruby に慣れていない人のコードだなと一目でわかるのが、 条件式で nil や false と明示的に比較している場合です。例えば次のように。
if @fp != nil thenif @headerset == FALSE thenこれは「if @fp」と「unless @headerset」にすべきです。 特にもともと真偽値である値を true, false と比較するのは時間の無駄です。 if の条件式はもともと真偽値を受け付けるのですから、 余計な比較を増やすのはやめましょう。
ちなみに、「if @headerset」では @headerset が真偽値かわからないだろ、 などという意見は本末転倒もいいところだと思います。 それは真偽値に見えない変数名が悪いのです。 条件式で工夫して悪いところを隠すのはやめてください。
nil の場合は明示的に比較したほうがいいよという人もいますが、 わたしは nil の場合も積極的に if @fp の形式を使います。 Ruby の if, unless は「存在するかどうか」をチェックする文法なんだと 脳内にビルトインされているので、特に不自然だとは感じません。
配列へのアクセス
オリジナルのコードには、 次のようにインデックスを使って配列にアクセスするコードが大量にありました。
count = 0
while count < (@fields.numfields) do
……
count += 1
end配列の全要素に順番にアクセスするのなら Array#each を使いましょう。 each を使うと次のようになります。
@fields.each do |field|
……
end一般的に言うと、次のようなコードは、
i = 0
while i < a.size
x = a[i]
……
i += 1
endeach を使って以下のように書き換えられます。
a.each do |x|
……
endeach にはカウンタを使うスタイルに比べて以下のような利点があります。
- 短い。単純。読みやすい。
- 無駄なカウンタが必要ない。
- 実は each のほうが速い。
このように、each の優位は明らかです。 配列や、それに類似したデータへの順次アクセスには常に each を使いましょう。
冗長な、あまりに冗長な
一時変数は少ないほうがいいというのは事実ですが、 何事にも限度というものがあるわけです。
typechar = @fields.item(@fields.fieldname(count)).fieldtype
if typechar == "N" or typechar == "F" then
@fields.item(@fields.fieldname(count)).value = @fp.read(@fields.item(@fields.fieldname(count)).fieldsize).to_f
elsif typechar == "C" then
@fields.item(@fields.fieldname(count)).value = @fp.read(@fields.item(@fields.fieldname(count)).fieldsize)さて @fields.item(@fields.fieldname(count)) は何度出てくるでしょうか。 これはさすがに一時変数に代入しておいたほうがよいと思います。
field = @fields.item(@fields.fieldname(count))
typechar = field.fieldtype
if typechar == "N" or typechar == "F" then
field.value = @fp.read(field.fieldsize).to_f
elsif typechar == "C" then
field.value = @fp.read(field.fieldsize)一時変数を嫌うなら、むしろ typechar を消すべきでしょうね。
field = @fields.item(@fields.fieldname(count))
if field.fieldtype == "N" or field.fieldtype == "F" then
field.value = @fp.read(field.fieldsize).to_f
elsif field.fieldtype == "C" then
field.value = @fp.read(field.fieldsize)ついでに if を case に変えればさらにスッキリします。
field = @fields.item(@fields.fieldname(count))
case field.fieldtype
when "N", "F"
field.value = @fp.read(field.fieldsize).to_f
when "C"
field.value = @fp.read(field.fieldsize)文字列のパディング
次はやや細かい話題です。 まずコードを見てください。
fieldnamelen = 0
fieldnamearr = @fields.fieldname(count).split(//)
while fieldnamelen < 11 do
if fieldnamearr.size > 0 then
@fp.write(fieldnamearr.shift)
else
@fp.write("\000")
end
fieldnamelen += 1
end何をしたいのかわかるでしょうか。 これは、fieldname が 11 バイトより短いときには 末尾に NUL 文字 (“\0”) を追加して 11 バイトにするコードです。
このコードは String#ljust を使うと劇的に単純化できます。
fieldname.ljust(11, "\0")ちなみに、ljust の第二引数が使えるようになったのは Ruby 1.8 からなので、 1.6 の場合はもう少し工夫する必要があります。
fieldname + ("\0" * (11 - fieldname.size))それでも二行以上にはなりません。
何度も言いますが、String のリファレンスマニュアルはぜひ眺めておいてください。
それから手前味噌ですが の文字列の章も役に立ちます。
の文字列の章も役に立ちます。
ファイルを行ごとに読む
短く書けるコードは他にもあります。 例えばこれです。
# 入力リストの取得
filelist = []
count = 0
fplist = open(listfile, "r")
while not fplist.eof
filelist[count] = fplist.gets.chomp
count += 1
end
infilenum = count
fplist.closeファイル listfile を読み込んで各行の改行文字を取り除き、 行ごとの配列にしています。
まず、ブロック付きの File.open が使えます。 ブロック付きのときはブロック終了とともに 自動的にファイルが close されるので、 明示的に close する必要がありません。
filelist = []
count = 0
File.open(listfile, "r") {|f|
until f.eof?
filelist[count] = f.gets.chomp
count += 1
end
infilenum = count
}ローカル変数 infilenum は配列 filelist のサイズと同じなので、 いつでも filelist.size で取れます。 また、配列の末尾に要素を追加していくなら push を使えば済むので count も必要ありません。 したがって両方とも消せます。
filelist = []
File.open(listfile, "r") {|f|
until f.eof?
filelist.push f.gets.chomp
end
}行ごとの読み込みには File#each (IO#each を継承) が使えます。
filelist = []
File.open(listfile, "r") {|f|
f.each do |line|
filelist.push line.chomp
end
}もうそろそろ無理ですかね? 無理ですよね。無理ですよ。
残念ながら甘すぎます。 ほとんどの場合、each と push の組み合わせは map に変更できます。
filelist = nil
File.open(listfile, "r") {|f|
filelist = f.map {|line| line.chomp }
}ここまで行けばあと一息です。 ファイル全体を行ごとの配列として読み込む File.readlines を使ってみましょう。
filelist = File.readlines(listfile).map {|line| line.chomp }またしても 1 行で済んでしまいました。
配列の全要素が条件を満たすか調べる
配列絡みでもう一発やりましょう。
# 入力したレコードを出力するかをチェック
# すべての文字型の指定フィールドに空白以外の値があるかで判定する
count = 0
validcount = 0
refccount = 0
while count < reffieldnum
if dbfin.fields(reffield[count]).fieldtype == "C" then
refccount += 1
if dbfin.fields(reffield[count]).value.gsub(" ", "") != "" then
validcount += 1
end
end
count += 1
end # while count < reffieldnum
# 文字型の指定フィールドのすべてに空白以外の値のある場合にレコードを出力する
if validcount == refccount then最後の if 文が何をやっているかわかるでしょうか。
まあコメントに書いてあるからわかるでしょうね。 「フィールドが文字列型ならば、値に空白以外の文字を含まなければならない」 という条件をチェックしているのです。 このコードでは「文字列型のフィールドの数 (refcount)」と 「値が空白以外の文字を含むフィールドの数 (validcount)」を数えて、 それが等しいかどうかでチェックしています。
まず、例によって count は each で置き換えます。 コメントもうざったいので消しましょう。
validcount = 0
refccount = 0
reffield.each do |name|
if dbfin.fields(name).fieldtype == "C"
refccount += 1
if dbfin.fields(name).value.gsub(" ", "") != ""
validcount += 1
end
end
end
if validcount == refccount条件部をメソッドに分割します。これは次の布石です。
def valid?(dbfin, reffield)
validcount = 0
refccount = 0
reffield.each do |name|
if dbfin.fields(name).fieldtype == "C"
refccount += 1
if dbfin.fields(name).value.gsub(" ", "") != ""
validcount += 1
end
end
end
validcount == refccount
end
if valid?(dbfin, reffields)dbfin.fields(name) をくくりだします。
def valid?(fields)
validcount = 0
refccount = 0
fields.each do |f|
if f.fieldtype == "C"
refccount += 1
if f.value.gsub(" ", "") != ""
validcount += 1
end
end
end
end
if valid?(reffield.map {|name| dbfin.fields(name) })一つでも条件に合わない (valid でない) フィールドがあったら その時点でメソッドの返り値は false になることを考慮しつつ、 メソッド内の条件判断二つを融合し、カウンタを一掃します。
def valid?(dbfin, reffields)
fields.each do |f|
if f.fieldtype == "C" and f.value.gsub(" ", "").empty?
return false
end
end
true
end
if valid?(reffield.map {|name| dbfin.fields(name) })次の変形は少々手強いかもしれません。
list.each do |x|
return false if cond?(x)
end
trueは、Enumerable#all? を使って
list.all? {|x| not cond?(x) }と書き換えられます。
def valid?(fields)
fields.all? {|f|
not (f.fieldtype == "C" and f.value.gsub(" ", "").empty?)
}
end
if valid?(reffield.map {|name| dbfin.fields(name) })あとは好みに応じてさらにメソッドを分割するなりなんなり、好きにしてください。
if valid?(needed_fields.map {|name| dbin.field(name) })
....
def valid?(fields)
fields.all? {|f| not invalid_field?(f) }
end
def invalid_field?(f)
f.string_field? and f.value.gsub(/ /, "").empty?
endエラーの通知
最初は、ライブラリ内で起こったエラーを通知する方法についてです。 以下が dbf.rb 内にあったコードです。
if openmode != "r" and openmode != "c" then
p "オプションのオープンモード [" + openmode + "] が不正です"
exit
end改善すべき点は二つです。
第一に、p は基本的にデバッグ用のメソッドなのでエラーメッセージを出すには適しません。 どうしてもエラーメッセージを出すなら $stderr.puts や $stderr.print を使いましょう。 また、アプリケーションのユーザではなく、 ライブラリを使うプログラマに気付いてほしいメッセージには warn を使いましょう。
第二に、ライブラリ内で exit すべきではありません。 ライブラリで exit してしまうと使い勝手が非常に悪くなるからです。 こういうときは例外を使いましょう。 このコードを例外を使って書き換えると次のようになります。
case openmode
when 'r', 'c'
……
else
raise ArgumentError, "invalid open mode: #{openmode.inspect}"
end引数が不正なときには ArgumentError を発生するのが適切です。 他の代表的な例外には以下のようなクラスがあります。
| 例外クラス | 意味 |
| ArgumentError | 引数の内容が不正である |
| TypeError | (引数の) 型が違う |
| IndexError | 配列などのインデックスが範囲外 |
| RangeError | C レベルにおいて、Bignum を Fixnum に変換しようとした、など |
| IOError | 入出力エラー |
| RuntimeError | その他の、一般的な実行時エラー |
もっとも、普通は ArgumentError くらいしか使わないと思います。 よりたくさんの情報を例外に乗せる必要があるときは、 自分で StandardError を継承して例外クラスを作ったほうがよいでしょう。
オプション解析
ライブラリの使用例として添付されていた dbfrecomb.rb はコマンドラインオプションを受け付けるようになっていました。 以下のように、ごく簡単に -h だけを処理しています。
if ARGV[0] == "-h" then
p "dbfrecomb ver. 0.2"
p "dbfrecomb [-opt] listfile outfile [reffield ...]"
p " opt:h help"
p " reffield reference field name"
p ""
p "(ex.) dbfrecomb listfile.txt outdata.dbf pntid name area"
p ""
p "listfile format:"
p "dbffile1.dbf"
p "dbffile2.dbf"
p " ..."
exit
endまず、p はやめましょう。ここは puts にすべきです。 また、複数行に渡る文字列はヒアドキュメントを使うと簡潔に書けます。
しかしせっかくの機会ですから、元のコードを利用するのではなく、 optparse.rb を使って「しっかりと」オプションを解析してみることにしました。 以下がわたしのコードです。
require 'optparse'
def main
additional = []
outfile = nil
parser = OptionParser.new
parser.banner = "Usage: #{$0} [-f NAME,NAME...] -o PATH input..."
parser.on('-f', '--fields=NAME,NAME', 'Adding field names.') {|names|
additional = names.split(',')
}
parser.on('-o', '--output=PATH', 'Name of output file.') {|path|
outfile = path
}
parser.on('--help', 'Prints this message and quit.') {
puts parser.help
exit 0
}
def parser.error(msg = nil)
$stderr.puts msg if msg
$stderr.puts help()
exit 1
end
begin
parser.parse!
rescue OptionParser::ParseError => err
parser.error err.message
end
parser.error 'no output file' unless outfile
parser.error 'no input file' if ARGV.empty?
infiles = ARGVoptparse.rb の基本的な使いかたは以下の通りです。
- require ‘optparse’
- とりあえずパーサを作る
-
parser.on(…) { arg …… } でオプションを登録 - parser.parse! で実際にパース
その他に知っておくとお得な情報としては、 以下のようなところでしょう。
- parser.help でオプションを自動的に要約した文字列を作ってくれる
- そのメッセージにコマンドの使いかたなどを追加したいときは parser.banner= で登録できる
これは見てみたほうが早いでしょう。 上記のコードを書いて –help オプションを付けてみると、 次のようなメッセージが出ます。
~/c/rubima/0013-CodeReview % ruby recomb.rb --help
Usage: recomb.rb [-f NAME,NAME...] -o PATH input...
-f, --fields=NAME,NAME Adding field names.
-o, --output=PATH Name of output file.
--help Prints this message and quit.「Usage:」の行が banner= で登録したメッセージで、 残りはオプションの定義から OptionParser が生成しています。
インターフェイスの改善
次はまた視点を上げてライブラリのインターフェイスを検討していきましょう。 オリジナルの dbf.rb のコード例は、 添付されていた dbfrecomb.rb からの引用です。
用語
最初に少し用語を定義しておきます。
データベースは「レコード (record)」の集まりです。 レコードというのは構造体みたいなもので、 いくつかの「フィールド (field)」から成ります。 同じ dBASE データベースに入っているレコードは すべて同じフィールドを持ちます。 つまり図に書くと「フィールド×レコード」のマトリックスになるわけです。
フィールドは型が決まっており、 データベースにはフィールドの型情報 (メタデータ) も保存されています。 このメタデータをまとめてデータベーススキーマ (database schema) と呼んでおきます。
データベースへの接続
以下本題です。
まずデータベースに接続しないと話になりません。 オリジナルのコードはこうです。
dbfin = DBFrecordset.new # ファイルごとにオブジェクトを生成する
dbfin.dbfopen(filelist[listcount], "r")
……
dbfin.close二つ不満があります。
- new と dbfopen の二段階が必要なのが不便
- close するのがめんどくさい
したがって、まず dbfopen は open に改名し、 インスタンスメソッドではなく特異メソッドとして使えるようにします。 また、open はブロックを受け取り、ブロックから抜けるタイミングで 自動的にデータベースを close するよう改善します。
この変更によって使いかたは次のように変わりました。
DBF::RecordSet.open(path, 'c') {|db|
……
}レコードへのアクセス
データベースに接続したらレコードにアクセスしましょう。 以下がオリジナルのコードです。
dbfin.movefirst
while not dbfin.eof
……
if dbfin.fields(reffield[count]).value.gsub(" ", "") != "" then
……
end
……
dbfin.movenext
endまず、DBFrecordset#eof と #movenext でループを作っておきます。 movenext メソッドを呼ぶたびに RecordSet には「現在のレコード」がロードされ、 レコード一つずつにアクセスできるようになるわけです。
DBFrecordset#fields で現在のレコードからフィールドオブジェクトが取り出せます。 fields メソッドの引数はフィールド名です。 そして DBFfield#value でそのフィールドの値が取り出せます。 例えば rainfall というフィールドがあるなら その値には次のようにアクセスできます。
dbfin.fields('rainfall').value今度は四つ不満があります。
- 最初の #movefirst がダルい
- #movenext を呼ぶのがダルい
- フィールドの値にアクセスする方法がダルい
- #eof は真偽値を返すんだから「?」を付けたい
以上を勘案して、次のように改善しました。
db.each_record do |rec|
rec.rainfall
endまずループは each_record 一発で書けるようにします。 ブロック引数は DBF::Record オブジェクトです。 このオブジェクトにはフィールド名と同じ名前のメソッドが定義されており、 そのメソッドでフィールドの値にアクセスできます。 例えば “rainfall” フィールドにアクセスしたければ 上記のように rec.rainfall で OK です。
また、日本語フィールド名など、 メソッドだと不都合が起きそうなフィールドに備えて、 rec[‘フィールド名’] でもアクセスできるようになっています。
なお、each_record によるアクセスは以下の略記です。
until db.eof?
rec = db.current
……
db.next
endこのインターフェイスを決めるにあたっては JDBC の API を参考にしました。
データベーススキーマの定義
参照側は以上で終わりです。 今度は定義・追加のほうを見てみましょう。
まず新しいデータベースを作るときは open(path, “c”) でデータベースを開いたあと、 次のようにフィールドを追加します。
dbfout.addfield(rainfallfield, "N", 10, 4)またしても気に食わない点があります。
- “N” がなんなのかわからない
この N は実は numeric の意味で、 フィールドに数値を格納することを示しています。 こういう謎の値はできるだけ避けたいものです。 添削後のコードでは次のようにメソッド名で フィールドタイプを指定できるようにしました。
dbout.add_numeric_field 'rainfall', 10, 4また、次のように他のデータベースのスキーマをそのまま使うこともできます。
dbout.add_field dbin.field('rainfall').dupちなみに addfield の残りの引数はサイズ指定で、 10, 4 は「整数部 10 桁、小数部 4 桁」の意味です。 これはこれでわかりにくいのでできれば改善したいですが、 そろそろ力尽きてきたので放置します。
データベーススキーマの参照
すでに定義してあるデータベーススキーマ (レコードの型) を参照することもできます。
dbfout.addfield(fieldname, dbfin.fields(fieldname).fieldtype, \
dbfin.fields(fieldname).fieldsize, dbfin.fields(fieldname).decimal)これだとどこが該当のコードなのかわかりにくいので、 もう少し人工的なコードも用意しておきました。
field = dbfout.fields(fieldname)
p field.fieldname
p field.fieldtype
p field.fieldsize
p field.decimalこのように、#fields で特定フィールドのスキーマが取れて、 そこから情報が得られるわけです。
今回は、すでに指摘したメソッド名の冗長さを除くと、 基本的な部分では不満はありません。 ただし fields というメソッド名は明らかに不適切です。 そこで次のように少し変えてみました。
field = db.field('rainfall')
p field.name
p field.type
p field.size
p field.decimalfields → field ではたいして違いませんが、 多少よくなったということで勘弁してください。
レコードの追加
最後にレコードの追加を見てみましょう。
dbfout.addnew
dbfout.fields(datefield).value = datetime[count]
dbfout.fields(rainfallfield).value = dbfin.fields(outfield[count]).value
……
dbfout.updateまず DBFrecordset#addnew で新しいレコードを追加します。 そのレコードのフィールドに書き込むには、 DBFrecordset#fields(フィールド名) でフィールドオブジェクトを取り出し、 field.value= で値をセットします。 最後に DBFrecordset#update でデータベースにレコードを書き込みます。
今回の不満は二つです。
- fields(name).value= という字面がダルい
- いかにも update を呼ぶのを忘れそう
以上の点と、参照側のインターフェイスも踏まえて 次のような使用例を作りました。
db.append {|rec|
rec.date = "2006-02-05T10:33:18"
rec.rainfall = 5213
}まずレコードを追加するメソッド append はブロックを取るようにし、 ブロックが正常終了したら自動的に update するようにします。 ブロック内で例外が発生したときは update せずに抜けます。 なお #append は以下の略記です。
rec = db.append
rec.date = "2006-02-05T10:33:18"
rec.rainfall = 5213
db.updateまた、フィールドの値の参照のときと同じように、 フィールド名と同名のメソッドでいきなり値を代入できるようにしました。
設計の改善
さて、ここからが本番です。 改良を加えたインターフェイスを目標として、 一気に内部を洗浄します。
dBASE IV 2.0 フォーマット
実装を見るにあたって、dBASE データベースのフォーマット (DBF フォーマット) をごく簡単に説明しておきます。
DBF ファイルは以下のような構造になっています。
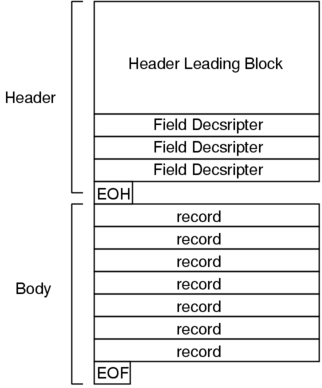
ファイルは大きくヘッダとボディに分かれます。 ヘッダはさらにリーディングブロックとフィールドディスクリプタに大別できます。 リーディングブロックにはファイルフォーマットのバージョンや最終更新日、 レコード数などの情報が格納されており、 フィールドディスクリプタはデータベーススキーマのことです。 ボディは見ての通りレコードが束になっているにすぎません。
また、ヘッダとボディの終わりにはそれぞれ特別なバイト EOH と EOF が入ります。
クラス構造
ではオリジナルのコードにどんなクラスとメソッドがあるのかざっと見ておきましょうか。 わたしはこういうときには rdefs というコマンドを使います。
~/c/rubima/0013-CodeReview % rdefs dbf.rb.org
class DBFheader
def initialize
attr_accessor :version, :date1, :date2, :date3, :numrec, :headerbytes, :recordbytes, :reserve
class DBFfield
def initialize
attr_accessor :fieldname, :fieldtype, :fieldsize, :decimal, :value
class DBFfields
def initialize
def add(fname, ftype, fsize, dec)
def fieldname(num)
def item(fname)
def numfields
class DBFrecordset
def initialize
def addfield(fname, ftype, fsize, dec)
def dbfopen(filename, openmode)
def eof
def close
def movefirst
def movenext
def addnew
def update
def numfields
def fieldname(num)
def fieldspec
def fields(fname)
def putheader
def writerecord
def readrecord
def moverecord(recno)
protected :putheader, :writerecord, :readrecord, :moverecordこの rdefs コマンドは [ruby-talk:28274] に 最初に登場したツールで、単純な実装ながら非常に使いでがあります。 ここで使っているのはそれをわたしが大幅に改造したものです (rdefs.rb)。
さて内容について議論しましょう。
まず DBFheader と DBFfield は実際のところ単なる構造体と変わりません。 おそらく Struct に置き換えても動いてしまうでしょう。 こういう何もしないクラスが絶対に必要ないとは言いませんが、 ほとんどの場合には設計が間違っています。
また DBFfields のコードをさっと眺めてみたところ、 このクラスはほぼ配列のラッパーにすぎませんでした。 このていどならば素の配列をそのまま使ってしまったほうが早いと感じるほどです。
一方 DBFrecordset クラスだけは異様に大きく、複雑そうです。 コードを眺めてみると、dbf.rb の機能のほとんどがこのクラスにつめこまれていました。 おそらく C 言語のような感覚で「構造体と、それを操作するコード」 のような設計をしてしまったのでしょう。
以上の観察を元に、次の点にポイントを絞ってリファクタリングすることにします。
- できるだけ DBFheader, DBFfield に機能を移転する
- DBFfields は廃止して配列を直接使う
- DBFrecordset から分離できるオブジェクトが見付かったら分離する
最終的には次のようなクラス構成に落ち着きました。
- DBF::HeaderLead
- DBF::Field
- DBF::RecordSet
- DBF::Record
まず、DBFheader は名前を HeaderLead と改名し、 単体でパースとシリアライズをこなせるようにします。 DBFfield も同様にパースとシリアライズの機能を追加します。 これで DBF::RecordSet をかなりダイエットできるはずです。 また、インターフェイスを改良した結果としてレコード一つを表現するクラスが必要になったので、DBF::Record クラスを新設しました。
型による分岐
続いて、さきほど改良したコードをさらに深く検討しましょう。
typechar = @fields.item(@fields.fieldname(count)).fieldtype
if typechar == "N" or typechar == "F" then
@fields.item(@fields.fieldname(count)).value = 0.0
elsif typechar == "C" then
@fields.item(@fields.fieldname(count)).value = ""
else
p "illegal type"
endこのコードはここまでの話を踏まえると次のように改善できるのでした。
field = @fields.item(@fields.fieldname(count))
case field.fieldtype
when "N", "F"
field.value = 0.0
when "C"
field.value = ""
else
raise ArgumentError, "illegal type"
endここで見たいのは fieldtype で明示的に分岐しているところです。 この類の分岐は、オブジェクト指向プログラミングの利点を語るときによく使われる、 「問題のあるコード」そのままですね。 フィールドの種類 (型) によって動作を変える必要があるのなら、 動作ごとにフィールドのクラスを分けましょう。 一言で言えば、ポリモルフィズムを活用するべきです。
添削後の該当するコードは以下の通りです。
field.load_default_value添削後のコードでは呼ぶ側に分岐が一切ありません。 フィールドの型の違いは field のクラスによって吸収されます。 具体的には、以下のように Field クラスを継承するクラスを三つ新設しました。
DBF::Field
DBF::NumericField
DBF::FloatField
DBF::StringField実装を全て見るのは無駄なので、 各クラスの load_default_value だけを見てみましょう。
class NumericField < Field
……
def load_default_value
@value = 0.0
end
end
class StringField < Field
……
def load_default_value
@value = ""
end
end見ての通りです。説明するまでもないでしょう。
protected
それから以前も扱った protected についてふれます。
#-----------------------------------------------------------------------
# 呼び出し制限
#-----------------------------------------------------------------------
protected :putheader, :writerecord, :readrecord, :moverecordこのような場合には protected ではなく private を使うべきです。 おそらく Java や C++ の protected と同じイメージで使ったのだと思いますが、 Ruby の protected は Java, C++ とは意味が違います。 Ruby の protected を使うと、サブクラスのインスタンスが 「オブジェクトの外から」メソッドを呼べるようになります。 つまり、次のような状況です。
class A
def m
puts "OK"
end
protected :m
def call_m(a)
a.m
end
end
A.new.call_m(A.new) # これは大丈夫
A.new.m # これはダメprotected が有効な場面はほとんどありません。 強いて言うと == を実装するときに他オブジェクトの内部データにアクセスしたいとか、 そのくらいでしょう。 外からの呼び出しを制限したいだけならば private が適切です。
class A
def m
puts "called"
end
private :m
end
A.new.m # m は呼べないちなみに、private に二種類の使いかたがあるのはみなさん御存知だと思います。 一つめは上記のようにメソッド名を明示する方法、 二つめは次のように領域を指定する方法です。
class A
private # これ以降のメソッドは private!
def m
puts "called"
end
end
A.new.m # m は呼べないこの二つのうちどちらを使うべきでしょうか。 わたしは public メソッドを上に書き private メソッドを下にまとめて書く癖があるので、 それに従って後者の方法を使っています。 毎回メソッド名を二回書くのがかったるいという理由もあります。
シリアライザの改善
長い長い第三回の添削もようやく終わりに近付いてきました。 これだけ長いと読むほうも疲れると思いますが、書いているほうはヘロヘロです。 5 時ですよ 5 時。そりゃ東の空も白んでくるっつーの。
さて最後の改善点はパーサとシリアライザです。 改善前・改善後いずれのコードもこの二つだけで ファイルの大部分を消費する重要パーツです。
ビフォアー
まず何も言わずにこれを見てください。
def putheader
@fp.seek(0, File::SEEK_SET)
#1 ヘッダ先導部
@fp.write("\003") # バージョンなど
@fp.write([Time.now.strftime("%y").to_i].pack("c")) # 最終更新日(年)
@fp.write([Time.now.strftime("%m").to_i].pack("c")) # 最終更新日(月)
@fp.write([Time.now.strftime("%d").to_i].pack("c")) # 最終更新日(日)
@fp.write([@numrecords].pack("l")) # レコード数
@headerlen = ((@fields.numfields + 1) * 32 + 1) # ヘッダのバイト数 ヘッダ先導部(32バイト)+Σフィールド記述部(32バイト) +1 ヘッダの終わりに1バイト付く
@fp.write([@headerlen].pack("s"))
count = 0
@recordlen = 1
while count < (@fields.numfields) do
@recordlen += @fields.item(@fields.fieldname(count)).fieldsize
count += 1
end
@fp.write([@recordlen].pack("s")) # レコードのバイト数 Σ((フィールド長)+1) レコードの先頭に削除フィールドが付く
@fp.write("\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000") # 予約領域など 20バイト出力
#2 フィールド記述部
count = 0
while count < (@fields.numfields) do
#フィールド名 (DBF ファイルの定義では11バイト)
fieldnamelen = 0
fieldnamearr = @fields.fieldname(count).split(//)
while fieldnamelen < 11 do
if fieldnamearr.size > 0 then
@fp.write(fieldnamearr.shift)
else
@fp.write("\000")
end
fieldnamelen += 1
end
@fp.write(@fields.item(@fields.fieldname(count)).fieldtype) # フィールド型 N,F:数値型、C:文字型
@fp.write("\000\000\000\000") # 予約領域 (4バイト)
@fp.write([@fields.item(@fields.fieldname(count)).fieldsize.to_i].pack("C")) # フィールド長
@fp.write([@fields.item(@fields.fieldname(count)).decimal.to_i].pack("C")) # 小数部の長さ
@fp.write("\000\000\000\000\000\000\000\000\000\000\000\000\000\000") # 予約領域など (14バイト)
count += 1
end # while count < (@fields.numfields) do
#2 ヘッダ部 (フィールド記述部) の終わりマーク (&H0D)
@fp.write("\x0d")
@headerset = TRUE # ヘッダ部を書き込んだ
end見た瞬間に「メソッド長すぎ、ゴチャゴチャしすぎ」という感想が浮かんできます。 また、すでに指摘した配列アクセスの問題もあります。 count は一掃しなければなりません。
しかし実は、メソッドを分割し、ここまでの問題をすべて修正しても、 このメソッドにはなお問題があります。 例えばコードの先頭付近に最終更新日をシリアライズしているコードがありますね。 次のところです。
@fp.write([Time.now.strftime("%y").to_i].pack("c")) # 最終更新日(年)さて、pack の ‘c’ はどういう意味だったか思い出せますか。 わたしは無理です。整数をパックしてるんだから整数だろうな、くらいしかわかりません。 まったく pack の意味不明さと来たら、 「pack のテンプレートがわからなくたって悔しくなんかないんだからな! バーカバーカ!」と幼児退行してみたくなるほどです。 そんな pack を使ったコードがえんえんと並ぶ様を見ているとそれだけでウンザリしてきます。 そのわかりにくさを補うためであろうコメントの山を見てまたさらにゲンナリします。
さらに悲しいのは、これが一度で済まないということです。 これはヘッダ書き込みのコードですから、 読み込みコードでもまた pack を連発してウンザリでゲンナリなコードを書かねばなりません。 これは明らかに問題です。二回もこんな面倒なコードを書いていたら、 いつテンプレートを間違えるか知れたものではありません。 コードが正しいことを確認するのも大変です。
アフター
では改善策を考えましょう。 まずは結論からお見せします。 改善の結果、次のように書けるようになりました。
def save_header
return unless header_modified?
@f.seek 0, File::SEEK_SET
@lead.last_modified = Time.now
@f.write @lead.serialize
@fields.each do |field|
@f.write field.serialize_schema
end
@f.write EOH
@header_modified = false
end衝撃の簡潔さです。 pack なんたらはどこへ行ってしまったのでしょうか。 実はすべて @lead.serialize の一行に押し込められているのです。 「完全に受動的な構造体 + シリアライズと I/O のコード」という構成を 「シリアライズできるオブジェクト + I/O」に変形したのですっきりとしました。 原則として I/O とそれ以外はきっちり分離したほうが設計がシンプルになります。
では serialize の定義はどうなっているのでしょう。 これがグチャグチャだったら意味がないはずです。 しかし、もちろんそんなことはありません。 serialize はこんなコードです。
def serialize
self.class.prototypes.zip(@alist.map {|_, val| val })\
.map {|proto, val| proto.serialize(val) }.join('')
end二行でした。 どうやらどこまで行っても pack でグチャグチャなコードは出てこないようです。
DSL
実は、今回も前回と同じような工夫をして、 pack 関係の記述はすべて DSL (Domain Specific Language) に押し込めているのです。 添削後バージョンでは、ヘッダリーディングブロックは以下のように記述されます。
# dBASE IV 2.0 file header leading block
#
# - filesize = header_size + (record_size * n_records)
# - header_size = HeaderLead.size + (Field.size * n_fields) + 1
#
HeaderLead = PackedStruct.define {
byte :magic # MSSSmVVV (M: dBASE III+/IV memo file,
# S: SQL table,
# m: dBASE IV memo file,
# V: format version)
byte :_year # last-modifield year - 1900
byte :month # last-modifield month
byte :date # last-modifield date
int32LE :n_records # a number of records
int16LE :header_size # byte-size of whole header
int16LE :record_size # byte-size of a record
string 2, :reserved1
byte :in_transaction
byte :encrypted
string 12, :reserved2
byte :mdx # 0x1: MDX; 0x0: no MDX
byte :langid # language driver ID
string 2, :reserved3
}HeaderLead#serialize と、それから HeaderLead.read は、 いずれもこのコードから自動的に定義されます。 つまり、仕様の記述に一切重複がありません。
また、仕様も一目瞭然です。byte, string, int16LE のような 可読性の高い記述が使えるので、プログラム自体で仕様を表現できます。 各フィールドの定義は以下の通りです。
| メソッド | 意味 |
| byte | 8 ビット整数 |
| int16LE | 16 ビット整数リトルエンディアン |
| int32LE | 32 ビット整数リトルエンディアン |
| string n | n バイトの文字列。余剰バイトは NUL パディング |
問題は、この PackedStruct がどう実装されているかです。
PackedStruct
PackedStruct の根本的なアイデアは簡単です。 バイナリデータなんてのは、ようするに、 pack 経由で読み書きできるフィールドがぎっちり詰まっているだけです。 ということは、pack で使うテンプレートがフィールドと 同じ順番に並んでいればそれで読み書きはできるはずです。
そこでまず、フィールド一つのメタ情報を保持するクラスを作っておきます。 以下の FieldPrototype がそれです。
class FieldPrototype
def initialize(name, template, size)
@name = name
@template = template
@size = size
end
attr_reader :name
attr_reader :size
def read(f)
parse(f.read(@size))
end
def parse(s)
s.unpack(@template)[0]
end
def serialize(val)
[val].pack(@template)
end
end見ての通り、FieldPrototype はフィールド名 (@name) と pack テンプレート (@template)、 それにバイトサイズ (@size) を保持しています。 サイズを pack テンプレートから計算できれば一つ変数が減ると考え、 ちょっとだけやってみましたが、 文字列が混じると思ったより面倒なのでやめました。
さて、FieldPrototype がフィールド一つ分の情報を持っているので、 これの配列を作れば pack された構造体の定義になります。 あとは、それをどうやって作るかです。
DSL の実装
そこで登場するのがさきほどお見せした DSL (Domain Specific Language) です。 あのコードから FieldPrototype の配列が作れれば 任務完了ということになります。
ではまず define から見ていきましょう。 コードは見やすいように少し変えました。
def PackedStruct.define(&block)
c = Class.new(self)
def c.inherited(subclass)
proto = @prototypes
subclass.instance_eval {
@prototypes = proto
}
end
c.module_eval(&block)
c
endまず、Class.new で self (例えば PackedStruct) を継承したクラスを作ります。
次にそのクラスに特異メソッド inherited を定義します。 inherited はそのクラスを継承するクラスを定義したときに Ruby インタプリタが呼ぶメソッドです。 ここでは FieldPrototype の配列 (@prototypes) をクラスの継承関係に沿って継承させています。 ぶっちゃけて言えば、Field の @prototypes を StringField などにコピーしたいというのがここの目的です。
最後に、module_eval を使って新しいクラスの上でブロックを実行します。 したがって、そのブロック中で byte, int16LE, string などが呼ばれると いま作ったばかりの新しいクラスに対してそのメソッドが呼ばれることになります。
次にその byte の定義を見てみます。
def PackedStruct.byte(name)
define_field name, 'C', 1
end
def PackedStruct.define_field(name, template, size)
(@prototypes ||= []).push FieldPrototype.new(name, template, size)
define_accessor name
enddefine_field の一行目で FieldPrototype の配列が作成されています。 (@prototypes ||= []) で配列 @prototypes を遅延初期化し、 FieldPrototype オブジェクトをつっこみます。 わかると思いますが、ここの @prototypes は クラスオブジェクトのインスタンス変数です。 インスタンスのインスタンス変数ではありません。
以上で FieldPrototypes の配列が用意できました。
構造体としての機能
あとは PackedStruct が構造体として働くようにするだけです。 ここからの話は DSL とはまったく関係ありません。
まず struct[‘field_name’] 形式でアクセスできるようにするところまでを見ます。
class PackedStruct
def initialize(*vals)
@alist = self.class.names.zip(vals)
end
def [](name)
k, v = @alist.assoc(name.to_s.intern)
raise ArgumentError, "no such field: #{name}" unless k
v
end
def []=(name, val)
a = @alist.assoc(name.to_s.intern)
raise ArgumentError, "no such field: #{name}" unless a
a[1] = val
end
……
endinitialize を見てください。 self.class.name はつまり PackedStruct.names で、 @prototypes からフィールド名を集めてきます。 それと、フィールドの値を zip します。
zip は知らない人が多いと思うので解説しましょう。 Array#zip は、二つ以上の配列 (レシーバと引数) を「横に」連結するメソッドです。 例えば上記のコードでは、 まずフィールド名の配列と値の配列があります。
["magic", "_year", "month", "date", "n_records"]
[ 3, 106, 2, 12, 256]これを zip すると次のようになります。
[ ["magic", 3],
["_year", 106],
["month", 2],
["date", 12],
["n_records", 256] ]まあ、直感的にわかるでしょう。 このようなペアの配列のことを alist (association list) と呼ぶことは前回も話しました。
このデータ構造さえわかっていれば PackedStruct#[] と PackedStruct#[]= はもはや恐るに足りないはずです。まあ、Array#assoc というマイナーメソッドがありますが……。 これは前回も話しましたし、リファレンスマニュアルでも見てください。
メソッドによるメンバアクセス
最後に、これまた前回と同じように、 メンバにメソッドでアクセスできるようにしましょう。 つまり struct[‘n_records’] を struct.n_records と書けるようにしたいのです。
これをやっているのが、 define_field の中で呼んでいた define_accessor です。 さきほど言ったように、いま話していることは DSL とは関係ありません。 ですから define_accessor を DSL の実装の中で呼ぶ必然性もありません。 例えば new の中で一回だけ全フィールド分の define_accessor を呼んでも問題はありません。 しかしそれよりは define_field の中で呼んでしまったほうが実装が楽だから、 そこに紛れ込ませてあるにすぎません。
さて実装を見てみます。
def define_accessor(name)
module_eval(<<-End, __FILE__, __LINE__ + 1)
def #{name}
self['#{name}']
end
def #{name}=(val)
self['#{name}'] = val
end
End
endこのように module_eval で一発です。
え、module_eval がわからない? リファレンスマニュアルを引いてください。以上、添削終了!
余談:永続化はいつも面倒だ
かようにパースとシリアライズは多くのプログラムで問題になってきます。 もうちょっと話を一般化すると、データの永続化 (persistency) の問題です。 バイナリデータなら型がどーとかエンディアンがなんたらで面倒ですし、 テキストデータならそれはそれで LL とか LR とかの話が出てきて面倒です。 任意のオブジェクトを永続化しようとするとリファレンスも扱う必要があります。 効率的に I/O を書くのもダルいことこのうえありません。
そうなると誰でも「汎用的な永続化ライブラリを作っておけば楽なんじゃね?」 ……と、考えるわけです。 Ruby on Rails の一部である Active Record もそんな努力の一種だと言えるでしょう。 Ruby オブジェクトの定義を規約で縛り、 自動的にリレーショナルデータベースへ出し入れできるようにしたのが Active Record だと思っておけば、まあ当たらずと言えども遠からず。 Active Record に限らず O/R マッパーと呼ばれる層は どれもそういう狙いのもとに作られています。
しかし永続化に使えるのはリレーショナルデータベースだけではありません。 最近わたしが気になってしかたないのがオブジェクト指向データベースです。 オブジェクト指向データベースは、あたかもメモリ上のオブジェクトを そのままディスクに保存したかのように動作します。 つまり、普段 Ruby プログラムで使っているオブジェクトが まさにそのままデータベースに入っており、 永続化されたオブジェクトはプロセスの壁を越えて共有できます。 また、データベースにもよりますが、 トランザクションやバージョン管理が使えることもあります。 そんな便利なオブジェクト指向データベースが、Ruby でも使え
……たらいいなぁ〜、と、思うのですが、 残念ながら Ruby で実用になるオブジェクト指向データベースは まだ見たことがありません。前々から作りたいなあと思ってはいるのですが……。
おわりに
いかがだったでしょうか。 今回のコードは基本的な部分から復習するにはなかなかよい題材です。 後半のゴチャゴチャはともかくとして、前半部分だけは確実に押さえておいてください。 余裕のあるかたはシリアライズ部分についてもあれこれ試してみるとよいでしょう。
最後に添削前・添削後両方のソースコードを置いておきます。 見比べてみてください。
- dbf.rb (オンラインで表示)
- dbfrecomb.rb (オンラインで表示)
- dbf2.rb (オンラインで表示)
- recomb.rb (オンラインで表示)
- CodeReview-0013.tar.gz (まとめてダウンロード)
次回予告
例によって予定は未定です。添削してほしいプログラムをお持ちのかたは Subject に「添削希望」と書いてるびま編集部にプログラムを送りつけてください。 ただし、添削するプログラムはオープンソースソフトウェアに限定します。 プログラムサイズの制限はありません。
ではまた次回の添削でお会いしましょう。
著者について
青木峰郎 (あおき・みねろう)
ふつうの文系プログラマ。本業はたぶん哲学。 主著『Ruby ソースコード完全解説』 『ふつうの Linux プログラミング』 『Ruby レシピブック』。 『ふつうの Haskell プログラミング』も近日発売……だと嬉しい。