あなたの Ruby コードを添削します 【第 4 回】 Tropy
著者:青木峰郎
編集:ささだ
- はじめに
- Tropy の読解
- Tropy::Database クラスの改善
- Tropy::Tropy クラスの改善
- HTMLテンプレートシステムの導入
- ウェブアプリケーションの設定はどーする委員会
- おわりに
- 著者について
- あなたの Ruby コードを添削します 連載一覧
はじめに
夏です。食中毒の季節です。
わたしも季節を感じるべく賞味期限を二週間すぎた卵にチャレンジしました。 サルモネラ菌が恐いのでさすがに火は通しましたが、卵は意外と保つので安心です。 なにしろ、 卵があっというまに腐ってしまうようではヒヨコは安心して生まれてこられません。 そう考えれば卵が腐りにくいのは自然です。 どうせチャレンジするなら、卵などよりは鮮魚や生肉にすべきでしょう。 わたしも鮮魚については一週間オーバーくらいの経験しかありませんので、 これからさらに研鑽を積みたいと思います。
今回のお題について
ではさっそく今回のお題説明に入ります。 今回のネタは Tropy というウェブアプリケーションです。
Tropy は、『‘Java 言語で学ぶデザインパターン入門’』などの著書で有名な 結城浩さん作のウェブアプリケーションです。 Tropy は Wiki に似たアプリケーションですが、 「トップページを見ると毎回違うページに飛ばされる」 という特徴があります。 その特徴から、Tropy を利用したサイトには スタティックな構造が生まれにくくなっています。
元々の Tropy は Perl で書かれていましたが、 のちに結城さん自身の手によって Ruby 版が作成されました。 今回添削するのはその Ruby 版 Tropy です。
この連載でウェブアプリケーションを扱うのは初めてですから、 今回はできるだけウェブアプリケーションにありがちな問題を中心に 考えていきたいと思います。
ソースコード
今回もまず添削対象のソースコードを示します。
- sample.cgi (オンラインで表示)
- tropy.rb (オンラインで表示)
- CodeReview-0015.tar.gz (添削前後をまとめたアーカイブ)
sample.cgi がエントリポイントで、tropy.rb がメインのコードです。 ライセンスは Ruby ライセンスなので、添削後のコードもそれに準じます。
Tropy の読解
まずは添削の前準備として、 Tropy の仕組みを簡単に調べておくことにします。
1 分でわかるウェブアプリケーションの仕組み
今回の添削は、ウェブアプリケーションの仕組みを 多少は知っていることを前提としています。 ですから、ここでウェブアプリケーションの 仕組みをごくごく簡単に解説しておきます。
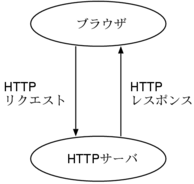
わたしたちが普段ウェブブラウザでページを見るときには、 ブラウザが裏でウェブサーバと通信しています。 ウェブサーバの代表例としては Apache, IIS, WEBrick などが挙げられます。
ブラウザでリンクをたどったり、ボタンを押したりするたびに
ブラウザはウェブサーバと通信して HTML や画像をもらいます。
その通信で使う規約が HTTP (HyperText Transfer Protocol) です。
ブラウザは「この URL のページをくれ」とか
「フォームの内容はこれだ」という内容を記述した「HTTP リクエスト」を送り、
それに対してブラウザが「HTTP レスポンス」を返します。
HTTP レスポンスは例えば HTML であったり、画像だったりします。
ウェブアプリケーションというのは、 以上のような仕組みを使って作られたアプリケーションのことです。 例えば tDiary とか Hiki、Gmail なども広くくくれば すべてウェブアプリケーションです。
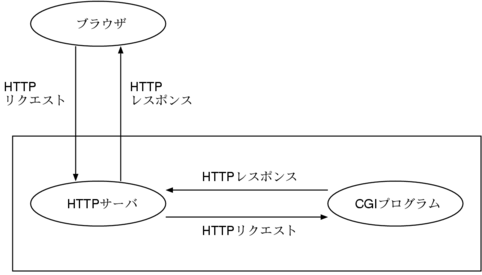
ウェブアプリケーションと CGI には深い関係があります。
CGI というのは、ウェブサーバから別のプログラムに
HTTP リクエストを渡す仕組みのことです。
CGI は UNIX 環境で最初にできたので、標準入出力と環境変数を利用しています。
Tropy の場合ならば、例えば Apache から Tropy プログラムを起動して
標準入力・環境変数経由で HTTP リクエストを渡し、
標準出力から HTTP レスポンスを受け取ります。
ちなみに FastCGI は名前付きパイプを使って、 一つのプロセスに何度も HTTP リクエストを渡せるようにした仕組みです。 mod_ruby はウェブサーバの中に Ruby インタプリタを組み込んでしまうことで プログラムに直接 (メモリ空間上で) HTTP リクエストを渡せるようにしています。
Tropy を使ってみる
さて、プログラムの仕組みを調べるとき、まず何をすべきでしょうか。 それは「実際に使ってみる」ことです。 あたりまえのようにも思えますが、 あまりにあたりまえすぎて、指摘してくれる人があまりいませんでした。 プログラムの仕組みを調べる前に、 まずはプログラムがどう動くのかちゃんと調べておきましょう。
書籍ならばここでスクリーンショットでも出して Tropy の使いかたを解説していくところです。 しかしせっかくウェブ雑誌で連載しているわけですから、 今回は実物を用意しました。 以下のリンク先に Tropy を動かしてありますので、 実際にさわってみてください。
ファイル構成
Tropy の挙動をおおむね理解した (と期待したい) ところで、 ソースコード読解に移りましょう。 Tropy のコードは以下の二つのファイルで構成されています。
- sample.cgi
- tropy.rb
sample.cgi がプログラムのエントリポイントです。 このファイルは非常に短いのでここで全部見せてしまいましょう。
#!/usr/bin/ruby
require "tropy"
ABSOLUTE_URL = "http://www.example.com/tropy/sample.cgi"
DATA_FILENAME = "/home/example/www/tropy/data/data.pstore"
MAX_COLS = 80
MAX_ROWS = 20
TITLE = "Tropy"
Tropy::Tropy.new(CGI.new, Tropy::Database.new(DATA_FILENAME))Tropy の設定はすべてこのファイルに直に書くようになっています。 設定ファイルやコマンドラインオプションはありません。 そして最後の一行で Tropy::Tropy オブジェクトを作成すると、 それと同時にアプリケーションが動作します。
また、CGI.new しているので、 Tropy は cgi.rb を使っているらしいこともわかります。
ところで、上記のコードでは tropy.rb が cgi.rb を require することを想定していますね。 わたしはそのような想定をするのはよろしくないと思います。 つまり、sample.cgi でも改めて require ‘cgi’ すべきだと思います。
cgi.rb は Tropy ライブラリとは別のライブラリなのですから、 Tropy が cgi.rb を使っているというのは暗黙の了解にすぎません。 したがって、「CGI」と書いてあったからと言って それが cgi.rb を使っている確証にはならないわけです。 しかし sample.cgi で require ‘cgi’ していればそのつながりは明確になります。
クラス構成
次に、tropy.rb に記述された各クラスを見ていきましょう。
tropy.rb には二つのクラスが定義されています。 Tropy::Tropy クラスと Tropy::Database クラスです。
Tropy::Database クラスは、名前から言って、 ページを記録しておくデータベースのクラスでしょう。 また Tropy::Tropy クラスは、さきほどの sample.cgi での使われかたからして、 アプリケーション自体を表現したクラスと予想できます (……というように、当たりをつけることもプログラマの重要な能力です)。
Tropy::Database クラスのほうが 具体的で相手にしやすいような予感がしますので、 このあとは Tropy::Database クラスから順番に見ていくことにします。
Tropy::Database クラス
最初は前回と同じように rdefs コマンドを使い、 クラスにどんなメソッドが定義されているのか眺めてみましょう。
% rdefs tropy.rb
module Tropy
class Database < PStore
def initialize(filename)
def empty?
def random_id
def create_id
def add_id(id)
def delete_id(id)
def set_msg(id, m)
def msg(id)
def title(id)
def body(id)
class Tropy
(……以下略……)この出力から、 Tropy はページの保存に pstore を使っているらしいことがわかります。 なぜなら Tropy::Database クラスが PStore クラスを継承しているからです。 御存知と思いますが、pstore は Marshal を利用したデータベースで、 マーシャル可能な Ruby オブジェクトならなんでも永続化できます。 非常に手軽で便利なライブラリです。
また、メソッド名を見るだけでも、 それぞれのメソッドが何をするのかだいたい想像がつきます。 例えば Database#empty? はデータベースにページが一つもないときに true を返すメソッドでしょう。
「なんとか_id」の「id」はページの ID (URL に含まれる) のことでしょうから、 Database#random_id はランダムなページ ID を作成するメソッドでしょう。
Database#title(id), body(id) は、それぞれ、 ページ ID が id であるページの「タイトル」「本体」 を返すような気がします。
その点、ちょっと動作を想像しにくいのが #create_id, #add_id, #delete_id, #msg, #set_msg の五つです。 例えば #create_id はページ ID を create するのでしょうが、 create_id と random_id がどう違うのかよくわかりません。 また、#delete_id、つまりページ ID を削除するメソッドがあるのに ページを削除するメソッドがないので、 ページがいつ消えるのかよくわかりません。 それから、#msg と #set_msg はそもそも msg (「メッセージ message」の略だろう) が何を意味するのかわかりません。
以上の疑問には今すぐ答えることはせず、 添削編であらためて問い直すことにします。
Tropy::Tropy クラス
次に Tropy::Tropy クラスを見てみます。 今度も rdefs で眺めてみましょう。
% rdefs tropy.rb
module Tropy
class Database < PStore
(……中略……)
class Tropy
def initialize(cgi, db)
def do_create
def do_read
def do_edit
def do_write(msg)
def editform
def content
def header(title, editable=nil)
def footer
def errorこれを見てまず目につくのは、#do_???? という名前のメソッド群です。 do のあとにひっついている単語は create, read, edit, write ですから、おそらくそれぞれの #do_???? が Tropy の 四つのコマンドに対応しているのだろうと考えられます。 「Tropy の四つのコマンド」とは、 「ページ作成」「ページ表示」「ページ編集」「ページ保存」 のことです。
また #editform, #content, #header, #footer あたりは それぞれページ編集用フォームやページ本体を出力する メソッドなんだろうなあーと想像できます。 そして最後に残った #error はエラーのハンドリング用でしょう。
以上をまとめると、Tropy#initialize から #do_???? のいずれかに飛び、 その中から #header, #content, #editform, #footer を順番に呼び出して HTML を出力する、という構造が浮かんできます。
このように、メソッド名を見るだけでプログラムの構造はだいたい想像できます。 それができるということは Tropy の設計は基本的によくできていると いうことなのですが、少し気になる点もあります。 あるのですが、それもやはり添削編で改めて指摘することにしましょう。
Tropy::Database クラスの改善
ではここから添削に入ります。 最初は Tropy::Database クラスを改善します。
継承
Tropy::Database クラスでまず気になる点は、 PStore クラスを継承していることです。 この手の継承の使いかたを見るとわたしは違和感を覚えます。 継承を使うのは、以下の 3 点を確認してからにしましょう。
- is-a 関係があるか
- 継承後もインターフェイスを維持しているか
- 実装を共有しているか
順番に詳しく話しましょう。
チェックポイント 1: is-a 関係
まず第一に、 スーパークラスとサブクラスは直感的に is-a の関係でなければいけません。 例えば Node と IfNode のように、 名前からして明らかに is-a だとわかる関係があるときに継承を使うべきです。
なぜなら、継承というのはそもそも is-a 関係を表すために使う機能だからです。 is-a でない関係を継承で表現してしまうと、非常にわかりにくくなります。
チェックポイント 2: インターフェイスの維持
第二に、継承後にもスーパークラスのインターフェイスを維持すべきです。 つまり、スーパークラスにあるメソッドはサブクラスでも維持すべきです。 継承後にメソッドを減らしたくなる場合は、 おそらく継承よりもコンポジションが適しています。
なぜなら、継承というのはそもそもインターフェイスを 「継承」するための機能だからです。 継承しておきながらインターフェイスは継承したくない、 というのは明らかな矛盾です。
チェックポイント 3: メソッドの実装の共有
第三に、これは Ruby の場合に限りますが、 スーパークラスとサブクラスがメソッドの実装を まったく共有しない場合は継承を使う必要はありません。
なぜなら、(Ruby の) 継承というのはそもそもメソッドの実装を 「継承」するための機能だからです。 継承しておきながらメソッドは継承したくない、 というのは明らかな矛盾です。
ただし、この第三点については 「使ってはいけない」とまでは考えていません。 実装を継承する必要がなければ無理に継承する必要はない、 というだけです。例えば Node クラスと IfNode クラスがあるとき、 実装を共有しないなら無理に継承しなくても問題はありませんが、 継承しても構いません。
Tropy::Database の継承チェック
では、Tropy::Database と PStore の場合は 上記のチェックポイント 3 点に照らして問題ないでしょうか。
まず第一点について。 Tropy::Database is a PStore、という関係が成立するでしょうか。 この関係はすでに怪しいと思います。 しかしまあ、場合によっては認めてもいいでしょう。
問題は第二点です。
実際にソースコードを見て確認してみると、
PStore から継承したメソッドを使っているのは、
ほぼ Tropy::Database クラス内のメソッドだけであることがわかります (下図参照)。
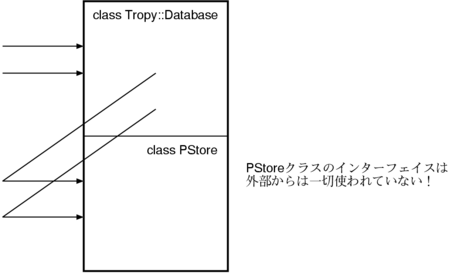
つまり、Tropy::Database クラスは
実質的に PStore のインターフェイスをすべて捨てているのです。
このような継承の使いかたは間違いです。
こういう使いかたをするなら、Tropy::Database は PStore を継承するのではなく、
インスタンス変数として持つべき (コンポジションにすべき) です。
そうすることで、以下のようにメソッドの流れが自然になります。
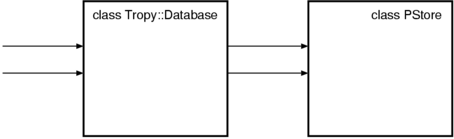
ついでに第三点についても言えば、 Tropy::Database は PStore のメソッドをすべて捨てているので、 同時に実装もすべて捨てています。 したがって Tropy::Database は第三点にも違反しています。
データモデルとしての整合性
次に、Tropy::Database のメソッド名に注目しましょう。 Tropy::Database には #msg(id) と #set_msg(id, m) というメソッドがあります。 調査編では「msg が何だかわからん」と文句をつけておきました。 結果だけ言うと、msg はページのソースコード (文字列) です。 つまり msg(id) はページ ID が id である ページのソースコードを取得するメソッドで、 set_msg(id, m) はページ ID が id であるページの ソースコードを保存するメソッドです。
この二つのメソッドは、 と []=(id, src) という名前のほうが適切だと思います。 つまり、database[id] と database[id] = src のように使えるべきだと思います。 そのほうが見栄えがよいですし、Tropy::Database にとって ページのデータが最も重要であることがよくわかります。
……と、書いたところで気付いたのですが、 元の Tropy::Database は下手に PStore を継承してしまったために、 [] や []= が (PStore がすでに定義しているために) 使えなかったという可能性がありますね。 正確に言えば [] と []= をオーバーライドすればいいのですが、 Ruby に慣れていなかったためにそのやりかたがわからなかったのだと想像します。 いずれにしても、PStore を継承したのは失敗でしょう。
既存オブジェクトへの「見立て」
さて、[] と []= がうまく定義できたということは、 Tropy::Database をハッシュに見立てて考えられるということに他なりません。 Tropy::Database オブジェクトは、ページ ID がキーで、 その内容のハッシュテーブルのようなものなのです。
そう考えてみると、他のメソッドも Hash に似せて作ると インターフェイスが想像しやすくなるのではないかと考えられます。 例えば Hash と同じように #delete や #empty? や #size や #keys や #values や #each が定義されていたら、 動作を容易に想像できるでしょう。
Tropy::Page オブジェクトの導入
Tropy::Database の #title, #body, #msg にも不満があります。 この三つのメソッドは、
- db.title(id)
- db.body(id)
- db.msg(id)
と、いうように使ってそれぞれ 「ページ ID が id であるページのタイトル」 「同ページの本体」 「同ページのソースコード」を返します。 しかし、一つのページのデータをバラバラに返すのはいただけません。 次のように、ページを表現するオブジェクトを導入すべきです。
- db[id].title
- db[id].body
- db[id].msg
なぜなら、ページには明らかに構造があるからです。 つまり、タイトルと本体があるということです。 もし、ページに構造がなく、単なる文字列一個で済み、 データベースクラスは文字列の中身には関らない―― という条件が成立するのならクラスを作らなくともよいと思います。 しかし、まがりなりにも構造があるのなら新しいクラスを作るべきです。 この、ページ一つを表現する新しいクラスを Tropy::Page クラスとしましょう。
random_id と create_id の二つのメソッドも Tropy::Page オブジェクトを扱うように変更できます。
まず random_id は「既存ページ ID をランダムに一つ選んで返す」 メソッドですが、Tropy::Page オブジェクトを前提とすると、 「既存ページの中からランダムに一つ選んで返す」メソッドに変更できます。 メソッド名は random に変えましょう。
同様に、新しいページ ID を作成する create_id メソッドは、 「新しくページオブジェクトを返す」メソッドに変更できます。 メソッド名は create としました。
インターフェイスの改善・まとめ
以上の変更を経て、Tropy::Database のインターフェイスは以下のようになりました。
class Database
def initialize(path, encoding)
def empty?
def [](id)
def []=(id, page)
def random
def create
def delete(id)initialize にこっそり encoding という引数が増えていますが、 些細なことなので気にしてはいけません。
また、Tropy::Page クラスのインターフェイスは次のようになりました。
class Page
def Page.parse(src, encoding = nil)
def Page.empty
def initialize(title, body, encoding = nil)
attr_reader :title
attr_reader :body
attr_reader :encoding
def body_htmlさほど驚くようなメソッドはないと思います。 ページのタイトル (title) と本体 (body) を そのままオブジェクトの属性にしただけです。 また Page.parse メソッドはページのソースコード src をパースして Page オブジェクトを作ります。 Page.empty メソッドは空のページに対応する Page オブジェクトを作ります。
ページ ID のリスト
さてそろそろ実装を見ていきます。 まず Tropy::Database#add_id と #msg(id) を見てください。
class Database < PStore
INDEX = "index" # id一覧保存用のキー
# idを追加
def add_id(id)
unless self[INDEX].index(id)
self[INDEX] << id
end
end
# idのページのメッセージ
def msg(id)
transaction(true) do
self[id.to_s].to_s
end
endここから以下の 3 点が読み取れます。
- ページ ID とページ自体 (文字列) は別に保存されている
- ページ ID は pstore[“index”] に配列で保存されている
- ページ自体は pstore[ページID] に保存されている
まず、ページ ID のリストを自分で独自に管理する必要はありません。 ページ ID は pstore のキーになっているので、 全ページ ID のリストは PStore#roots で得られるからです。 したがって、ページ ID のリストを別に管理するための メソッド #add_id, #delete_id は不要です。
複数の操作は複数のメソッドで
次に Tropy::Database#set_msg のコードを見ます。
# idのページにメッセージmを保存
def set_msg(id, m)
id = id.to_s
m = NKF::nkf(NKF_OPTION, m.to_s)
transaction do
if m.length > 0
self[id] = m
add_id(id)
else
self.delete(id)
delete_id(id)
end
end
endこのメソッドはページ ID が id のページを保存します。 ただし、ページの長さが 0 のときにはそのページを削除します。 つまり、ページの保存と削除という二つの操作が 一つのメソッドに同居しているわけです。
二つの操作を一つのメソッドで済ますべきではありません。 保存と削除はまったく違う操作なのですから、メソッドも分けるべきです。 「ページが空だったらそのページを削除する」という挙動は、 ウェブアプリケーションの仕様としてなら問題ないと思いますが、 それをデータベースレベルで実装する必然性はありません。 むしろ、データベースのような「下の」階層はできるだけ厳密な仕様にしておき、 Tropy::Tropy クラスのような「上の」階層で リクエストを解釈してやるべきでしょう。
Tropy::Tropy クラスの改善
この節では Tropy::Tropy クラスを改善します。
クラス名
まず最初に、Tropy::Tropy というクラス名に文句を付けたいと思います。 わたしは同じ名前を 2 回重ねるのがあまり好きではありません。 Tropy::Application とか Tropy::CGI とかのほうが好みです。
可視性を活用する
rdefs の出力を見て秘かに気になっていたのが、 private がまったく使われていないことです。 もう一度 rdefs の出力を見てください。
% rdefs tropy.rb
module Tropy
class Database < PStore
(……中略……)
class Tropy
def initialize(cgi, db)
def do_create
def do_read
def do_edit
def do_write(msg)
def editform
def content
def header(title, editable=nil)
def footer
def error可視性の指定があれば、ここで出てくるはずです。 それがないということは、 tropy.rb では可視性が一切指定されていないということです。
しかし、実装として可視性を指定する必要がないとは言えません。 もし private を使うなら、次の位置に指定するのが適切です。
% rdefs tropy.rb
module Tropy
class Database < PStore
(……中略……)
class Tropy
def initialize(cgi, db)
private
def do_create
def do_read
def do_edit
def do_write(msg)
def editform
def content
def header(title, editable=nil)
def footer
def errorつまり、Tropy::Tropy クラスのメソッドはすべて private、ということです。 Tropy::Tropy オブジェクトのメソッドは外部からは一切呼ばれないので、 すべて private メソッドにしてしまっても大丈夫なのです。
new を活躍させすぎない
ただし、そうなると今度は別の疑問が浮上してきます。 「外からメソッドを全然呼ばれないオブジェクトって意味あんのか?」 という疑問です。結論から言うと、ダメです。全然ダメです。ダメ。ゼッタイ。
そもそも Tropy::Tropy クラスはクラスにする意義がありません。 インスタンスは実質的に一つしか作れないし、メソッドも呼ばれないからです。 現在のように無理矢理クラスを作るくらいなら、Tropy::Tropy のメソッドを すべてトップレベルに定義してしまったほうがまだマシです。
こんなことになってしまう原因の一つは、 Tropy::Tropy.new の仕事が多すぎることでしょう。 以下に Tropy::Tropy.new のコードを示します。
def initialize(cgi, db)
@db = db
begin
cgi.params.each_key do |k|
if k =~ /^(\d{8})$/
@id = $1
do_read
elsif k =~ /^e(\d{8})$/
@id = $1
do_edit
elsif k =~ /^w(\d{8})$/
@id = $1
do_write(cgi.params["msg"])
elsif k =~ /^c$/
@id = @db.create_id
do_create
end
end
unless @id
if @db.empty?
@id = @db.create_id
do_create
else
@id = @db.random_id
do_read
end
end
rescue
print error
end
endTropy::Tropy.new は、CGI パラメータを解析して (前半)、 そのパラメータに従って適切な HTML を出力します。 つまり Tropy アプリケーションの仕事を全部やるわけです。
new はあくまで new なのですから、オブジェクトを作ることに専念すべきです。 オブジェクトを new しただけで仕事が全部片付くような設計にすべきではありません。 せめて次のように仕事を main メソッドにでも分割して胡麻化してくれたほうが、 まだ発展の余地が残ります。
def initialize(cgi, db)
@cgi = cgi
@db = db
end
def main
begin
# 略
rescue
print error
end
endこの形になっていれば、 あとで Tropy::Tropy オブジェクトに別の仕事をさせたくなっても簡単です。 例えば CGI 以外に FastCGI もサポートしたくなったとしても、 FastCGI をサポートする Tropy::Tropy#fcgi_main を定義して、それを使えば済みます。
しかし new でいきなり作業を始めてしまった場合、 それ以外の仕事を実行する余地が残りません。 ですから、他の仕事を追加するのが非常に厄介になってしまうのです。
ちなみに、new(CGI.new, db).main と書くのが面倒だと言うのなら、 クラスメソッドの main を追加するという手もあります。 つまり、Tropy::Tropy.main(CGI.new, db) と書けるようにするわけです。
Tropy::Tropy.main を定義するには次のように書きます。
class Tropy
def Tropy.main(cgi, db)
new(cgi, db).main
endこのやりかたならば他の仕事を追加する余地を残しつつ、 手軽な書きかたも追求できます。
インスタンス変数よりも引数を使う
次に、もう一度 Tropy::Tropy#initialize を見ましょう。
def initialize(cgi, db)
# ……略……
cgi.params.each_key do |k|
if k =~ /^(\d{8})$/
@id = $1
do_read
elsif k =~ /^e(\d{8})$/
@id = $1
do_edit
elsif k =~ /^w(\d{8})$/
@id = $1
do_write(cgi.params["msg"])
elsif k =~ /^c$/
@id = @db.create_id
do_create
end
endこのコードで非常に気になるのがインスタンス変数 @id の使われかたです。 @id は、#initialize から #do_???? に情報を渡すためだけに使われています。 このように、特定メソッドから特定メソッドへ情報を渡すためだけに インスタンス変数を使う手法は、明らかに「濫用」に含まれます。 特に Tropy の場合はメソッドの引数として渡すのは簡単ですから、 単にデータを受け渡すためだけにインスタンス変数を使うべきではありません。
改善後のコードは次のようになります。
def initialize(cgi, db)
# ……略……
cgi.params.each_key do |k|
if k =~ /^(\d{8})$/
do_read $1
elsif k =~ /^e(\d{8})$/
do_edit $1
elsif k =~ /^w(\d{8})$/
do_write $1, cgi.params["msg"]
elsif k =~ /^c$/
do_create @db.create_id
end
endいきなり出力しない
次に Tropy#do_create を見てください。
# 新規ページ作成フォームを表示
def do_create
print header("New Page"), editform, footer
endこのようにオリジナルの Tropy はページを いきなり print で出力していますが、一般に、 CGI プログラムでいきなり HTTP レスポンスを出力するのは避けるべきです。 このやりかただと Content-Length を出力できないことが増えますし、 FastCGI やサーブレットにも対応できません。 結果はいったん文字列にためておき、最後の最後で出力するようにすべきです。
BEGIN
最後におまけです。 tropy.rb の先頭付近に次のような文があるのですが……
BEGIN { $defout.binmode }ファイルのトップレベルで BEGIN を使ってもたいして意味はありません。 Ruby の BEGIN は「そのファイルで一番最初に実行される」文を登録する文なので、 中身をファイルの一番最初に書いておけば十分です。
ついでに言うと $defout は Ruby 1.9 では obsolete になっていますので、 $stdout を使ったほうが互換性が上がります。
HTMLテンプレートシステムの導入
この節ではテンプレートシステムを導入して HTML をソースコードから分離します。
動機
今度は Tropy::Tropy#header メソッドを見てみましょう。 このメソッドは HTML のヘッダ部分を文字列で返します。
def header(title, editable=nil)
edit = editable == :editable ? %Q(<a href="?e#{@id}">Edit</a>) : ''
create = %Q(<a href="?c">Create</a>)
random = %Q(<a href="#{ABSOLUTE_URL}">Random</a>)
<<-"EOD"
Content-type: text/html; charset=#{CHARSET}
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.or
g/TR/html4/loose.dtd">
<html lang="ja">
<head>
<meta http-equiv="content-type" content="text/html; charset=#{CHARSET}">
<meta http-equiv="content-style-type" content="text/css">
<base href="#{ABSOLUTE_URL}">
<style type="text/css"><!--
body{font-family:Verdana,sans-serif;margin:2% 20% 10% 20%;color:black;background
-color:white;}
input{font-family:Verdana,sans-serif;}
#navi{text-align:right;}
p{line-height:150%;}
a{color:gray;background-color:white;text-decoration:none;}
a:hover{text-decoration:underline;color:white;background-color:gray;}
--></style>
<title>#{title} - #{TITLE}</title>
</head>
<body>
<p id="navi">#{edit} #{create} #{random}</p>
<h1>#{title}</h1>
EOD
endこのようにメソッドに直接 HTML を埋め込むのは手軽ですし、 ファイルが増えすぎないのも利点です。 ですから、開発の初期にこのやりかたを使うのは問題ないと思います。
しかし、やはり HTML をソースコードに直接書いておく方法は柔軟性が低すぎます。 特に、プログラマ以外が HTML を編集する可能性がある場合には、 HTML はソースコードから分離しておくべきでしょう。
この節ではテンプレートシステムを導入して HTML をソースコードから分離します。
実装の概要
今回の添削では、あまり深く考えず eRuby を 使って HTML をテンプレート化することにしました。 また、テンプレートシステムの実装として以下の三つのクラスを導入します。
- Screen
- ScreenManager
- TemplateRepository
Screen オブジェクトは eRuby テンプレートを eval するときの self です。 実際にはテンプレートごとに別のサブクラスを作ります。 例えば read コマンドに対するレスポンスのためには ViewPageScreen クラスを使います。
ScreenManager オブジェクトは Screen オブジェクトを作成します。 各 Screen オブジェクトに適切なパラメータを渡すために用意しました。
TemplateRepository クラスは HTML テンプレート (文字列) をロードします。 実際のファイル配置を Screen オブジェクトから隠蔽するために導入しました。
Screen オブジェクトの入手
では、「ページを表示」する Tropy コマンドの実装である、 handle_view メソッド (元 do_read メソッド) から流れを追って見ていきましょう。
def handle_view(id)
page = @db[id]
return handle_create() unless page
@screenmanager.view_page_screen(id, page)
endまず、表示すべきページオブジェクトを @db[id] で取得し、 @screenmanager.view_page_screen で ViewPageScreen オブジェクトを入手します。 ScreenManager#view_page_screen は以下のようなメソッドです。 パラメータを渡して ViewPageScreen オブジェクトを作成します。
def view_page_screen(id, page)
ViewPageScreen.new(@params, id, page)
endこのように、view_page_screen メソッドは ViewPageScreen オブジェクトを作っているだけです。 ちなみにここで渡している @params には CSS の URL など、 HTML 生成に必要な情報がまとめられています。
ViewPageScreen クラス
ViewPageScreen オブジェクトは Screen オブジェクトの一種です。 Screen クラス群の継承関係はかなりややこしく、 以下のような親子関係があります。
- Screen
- TemplateScreen
- PageBoundScreen
- ViewPageScreen (*)
- EditPageScreen (*)
- RedirectScreen (*)
- PageBoundScreen
- ErrorScreen (*)
- TemplateScreen
実際に使われるのは (*) が後置された四つのクラスだけで、 残りはすべて抽象クラスです。
Screen クラスの実例として、さきほどコードに登場した ViewPageScreen クラスのコードを以下に示します。 なお、以下のリストではわかりやすくするため、継承したメソッドもすべて ViewPageScreen のメソッドであるかのように表示しています。
class ViewPageScreen
def initialize(params, id, page)
@params = params
@urlmapper = manager.urlmapper
@template_repository = manager.template_repository
@id = id
@page = page
end
def content_type
"text/html; charset=#{@page.encoding}"
end
def http_response
body = body()
out = StringIO.new
out.puts "Content-Type: #{content_type()}"
out.puts "Content-Length: #{body.length}"
out.puts
out.puts body
out.string
end
def body
run_template('view')
end
private
def run_template(id)
erb = ERB.new(@template_repository.load(id))
erb.filename = id
erb.result(binding())
end
alias h escape_html
def escape_html(s)
CGI.escapeHTML(s)
end
endさきほど handle_view で作成された ViewPageScreen オブジェクトは handle_view → handle → cgi_main と返されていき、 最終的に cgi_main が #http_response メソッドを呼びます。 そこから #body が呼ばれ、#body が #run_template を呼んだところで eRuby テンプレートに制御が移ります。
eRuby テンプレート
そこで次に、ページ表示リクエストに対する eRuby テンプレートを見てみましょう。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html lang="ja">
<head>
<meta http-equiv="Content-Type" content="<%=h content_type() %>">
<link rel="stylesheet" type="text/css" href="<%=h @params.css_url %>">
<title><%=h @page.title %> - Tropy</title>
</head>
<body>
<p id="navi">
<% if editable? %><a href="<%=h @urlmapper.edit(@id) %>">Edit</a><% end %>
<a href="<%=h @urlmapper.create %>">Create</a>
<a href="<%=h @urlmapper.drift %>">Random</a>
</p>
<h1><%=h @page.title %></h1>
<%= @page.body_html %>
</body>
</html>このように、テンプレートでは @params や @page の属性を適当にひっぱってきて表示します。 このへんは純粋に新規設計なので、あまり詳しくは話しません。
ウェブアプリケーションの設定はどーする委員会
続いてはウェブアプリケーションの設定について考えます。
設定ファイルは必要か
オリジナルの Tropy では sample.cgi ですべての設定を行っていました。 これに対して多くのウェブアプリケーションでは プログラムから設定ファイルを分離しています。 Tropy ではどちらの手法を使うのが適切でしょうか。
わたしが設定ファイルを作るときの規準は、 二つ以上のアプリケーションから一つの設定を使うかどうかです。 二つ以上のアプリケーションから使われる可能性があるのなら、 設定ファイルを分離すべきです。 そうでないのなら設定ファイルを分離する必要は感じません。 ただし、この場合は「してはいけない」とまでは思いません。
CGI アプリケーションで設定ファイルが必要ないと思うのは、 Tropy で言う sample.cgi を全くいじらずに済む場合があまりないからです。 例えば shebang line (#! の行のこと) はいかにも編集されそうですし、 Ruby プログラムであれば require する前にロードパスを追加したいことが多いでしょう。 そのような事情があるので、あえて設定ファイルを分離する意味はあまり感じないわけです。
さて Tropy では設定ファイルを分離すべきでしょうか。 わたしとしては、分離すべきだと思います。 現時点では設定を利用するアプリケーションは sample.cgi だけですが、 他に同じ設定が必要なアプリケーションはいくらでも考えられます。 例えば FastCGI 用の Tropy を作ればファイルが増えますし、 データベースをメンテナンスするコマンドがあってもいいかもしれません。
以上の理由から、Tropy でもコマンドから設定ファイルを分離すべきだと考えます。
設定ファイルのフォーマットは何にするか
次に、設定ファイルのフォーマットを何にするか考えましょう。 大雑把に言って、設定ファイルのフォーマットとして三つの選択肢があると思います。
- YAML や XML のような汎用フォーマット
- 独自のフォーマット
- Ruby スクリプト
一つめは、YAML や XML のように汎用で有名なフォーマットを使うことです。 Java の世界だといろいろなプログラムが XML で 設定ファイルを書かせるようになっていますし、 Lightweight Language 関係の新しいツールは YAML を使うものも増えてきています。 Windows 方面に目を向ければ昔懐かしい .ini フォーマットもありますね。
YAML や XML を使う利点は、 設定ファイル自体を再利用するのが容易だということです。 XML ならば書き換えルールを宣言的に記述できる XSLT が使えますし、 YAML は Ruby など様々な言語を使って変形可能です。
二つめは、アプリケーションごとに独自のフォーマットを使う方法です。 この手法の例としては httpd.conf や inetd.conf が挙げられるでしょう。 UNIX にはこの手の設定ファイルが腐るほどあります。
独自フォーマットを使う利点は、正直なところあまり思い付きません。 それぞれのアプリケーションに特化したフォーマットだけに、 設定を簡潔に書けると期待したいところですが、 実際に記述が簡潔かと言うと……控えめに言って、とても疑問です。 また、inetd.conf のように逆に簡潔すぎてわかりにくいこともあります。 さらに、他のプログラムから設定を生成したり、再利用したりするのも面倒です。 各ホストごと・各アプリケーションごとに 独自の世界を築いていればよかった時代にはともかく、 もういまのようになんでもかんでもシステムに溶け合ってきている状況では、 独自フォーマットの設定ファイルはウザったいだけだと思います。
三つめは、Ruby スクリプトをそのまま設定ファイルとして使うやりかたです。 このやりかたは、Ruby の世界に閉じるという代償こそありますが、 とても手軽ですし、少なくともプログラマにとっては便利です。
Tropy の場合は、まあ順当に Ruby スクリプトを使うのが楽でしょう。
どこから受け取るか
プログラムの設定に Ruby スクリプトを使うと決めた場合には、 具体的な手法がまたいくつかあります。 既存アプリケーションに見られる手法は以下のいずれかに分類できるでしょう。
- グローバル変数
- 定数
- インスタンス変数
- メソッド
- その他
順番に解説していきます。
グローバル変数
まず、最もお手軽ではあるができるだけ避けたいのが、グローバル変数を使う方法です。 例えばデータベースの場所を知りたいと思ったら、 設定ファイルを load して $DATABASE_DIR などを見る方法です。 この方法は旧バージョンの Hiki などで用いられていました。
グローバル変数を使う方法の問題は、グローバル変数自体にまつわる問題とほぼ同じです。 つまり、どこで設定を見ているかも、いつ値が変更されるかもわからないことです。 コードを追うのも難しくなりますし、データの流れを真面目に考えなくなりがちです。
また、グローバル変数を使うコードは意図しないバグを出しやすくなります。 なぜなら、Ruby では間違った名前のグローバル変数を参照しても エラーにもならないし警告も出ないからです。未定義の変数を参照した場合、 ローカル変数ならエラーになりますし、インスタンス変数では警告が出ます。 しかしグローバル変数を使っていた場合、 $DATABASE_DIR を見るつもりで $DATEBASE_DIR を見ていたー、 なんてバグで 1 時間を無駄に費すことになるかもしれません。
以上の理由から、グローバル変数を使って設定を読み込む方法はお勧めできません。 以下に述べる手法のいずれかを使うよう推奨します。
定数
二つめの方法は、設定ファイルを module_eval して定数から値を受け取ることです。 例えば設定ファイルを次のような内容にしておいて、
# file names
CHAPS_FILE = 'CHAPS'
INDEX_FILE = 'INDEX'
WORDS_FILE = 'REJECT'
NOCODE_FILE = 'NOTT'
# page volume
LIST_LINES_PER_PAGE = 40
TEXT_LINES_PER_PAGE = 37
TEXT_BYTES_PER_LINE = 74 # 全角37文字次のようにモジュール上にロードします。
def load_config_file(path)
mod = Module.new
mod.module_eval File.read(path)
mod
end値を参照するときは通常通り「::」が使えます。
mod = load_config_file('PARAMS')
p mod::CHAPS_FILEこの、定数を使う方法は、 わたしの書いた ReVIEW という執筆支援システムで使いました。
定数を使う方法の利点は、設定ファイルをうまく書けば Makefile やシェルスクリプトと変数を共有できることです。
逆に欠点としては、設定項目を変えたくなったときの対応が ちょっとめんどくさい、という点が挙げられます。 例えば上記の設定例で、 LIST_LINES_PER_PAGE (1ページに入るリストの行数) などの値はすべて判型 (B5 変形とか A5 とか) から決めるように変えたとしましょう。 そうすると、プログラムで mod::LIST_LINES_PER_PAGE にアクセスしていた部分をすべて書き換えなくてはいけなくなります。 ですから、設定に定数を使う場合、 アプリケーション側からは直接定数にアクセスせず、 以下のようになんらかのオブジェクトにラップして使うべきです。
class Config
def Config.load(path)
mod = Module.new
mod.module_eval File.read(path)
new(mod)
end
def initialize(mod)
@mod = mod
end
def list_lines_per_page
@mod::LIST_LINES_PER_PAGE
# または @mod::PAPER_SIZE から計算
end
end
config = Config.load('PARAMS')
p config.list_lines_per_pageなお、設定ファイルを module_eval ではなく load で読むのはやめましょう。 定数をグローバルに定義してしまったら、それはほとんどグローバル変数と同じです。
インスタンス変数
三つめの手法は、インスタンス変数を経由して値を受け取るやりかたです。 例えば次のような設定ファイル diary.conf を用意しておいて、
@data_path = '/var/tdiary'
@cache_path = '/var/cache/tdiary'
@secure = false
@multi_user = false
@lang = 'ja'
@index = './'
@update = 'update.rb'
@style = 'tDiary'次のように instance_eval を使ってオブジェクト上にロードします。
class Config
def Config.load(path)
c = new()
c.instance_eval File.read(path)
c
end
attr_reader :data_path
end
config = Config.load('diary.conf')
p config.data_pathこの手法は tDiary や Hiki で使われています。
インスタンス変数を使う手法の利点は、 必然的に設定をラップするクラスを作ることになるので、 アプリケーションが直接設定にさわることが減るという点です。 例えば上記の設定例で、 @cache_path が nil なら代わりに @data_path の値を使うとしましょう。 インスタンス変数を使う方法を使っていれば次のように簡単に対応できます。
class Config
def cache_path
@cache_path || @data_path
end
endなお、tDiary では method_missing を使って、 アクセサメソッドを定義しなくともインスタンス変数を参照できるようにしていますが、 そのような工夫はできるだけ避けるべきです。 ソースコードを読む人間にしてみると、Config オブジェクトに どんなパラメータが定義されているのかさっぱりわからなくなってしまいます。
メソッド
これまでの方法には共通する特徴があります。 まず第一に、どれも設定項目を変数なり定数なりにバラバラに入れるということ。 第二に、すべての設定項目を一つの名前空間に集中させているということです。
しかし、設定した項目は、最終的には、 いろいろなオブジェクトに分散されるのが普通です。 例えば @data_path の値はデータベースに、 @index はテンプレートシステムに、それぞれ渡されるべき値です。
また、アプリケーションが欲しいのは設定項目ではなく、 設定項目をうまく設定されたオブジェクトのはずです。 それなら最初からオブジェクトをくれたほうが早いでしょう。
そのような、オブジェクトをいきなり作って渡す手法は WEBrick で採用されています。 例えば以下のコード片はわたしが家庭内サーバで動かしている WEBrick の設定です。
server = WEBrick::HTTPServer.new(
:DocumentRoot => "#{server_root()}/tree",
:Port => port,
:Logger => new_logger(),
:AccessLog => access_log()
)さらに、わたしの作った BitChannel という Wiki では この方式を設定ファイルで使ってみました。 次のような設定ファイル config を用意しておき、
def bitchannel_context
cgidir = File.dirname(File.expand_path(__FILE__)).untaint
vardir = "#{cgidir}/var"
config = BitChannel::Config.new(
:site_name => 'LoveRubyNet Wiki',
:logo_url => 'logo.png',
:templatedir => "#{cgidir}/template",
:locale => BitChannel::Locale.get('ja_JP.eucJP'),
:cgi_url => '/~aamine/bc/',
:theme => 'default',
:use_html_url => false
)
repository = BitChannel::Repository.new(
:cmd_path => '/usr/bin/cvs',
:wc_read => "#{vardir}/wc.read",
:wc_write => "#{vardir}/wc.write",
:cachedir => "#{vardir}/cache",
:logfile => '../cvslog'
)
BitChannel::WikiSpace.new(config, repository)
endアプリケーション側では以下のようにロードします。
load './config'
wiki = bitchannel_context()この手法の利点は、とにかくアプリケーション側が楽ということです。 なにしろ設定をロードするだけでもうオブジェクトができているので、 あとはアプリケーションを開始するだけです。 例えば BitChannel の CGI アプリケーション用 エントリポイントは以下のように 4 行しかありません。
load './bitchannelrc'
setup_environment
require 'bitchannel/cgi'
BitChannel::CGI.main bitchannel_context()この手法の欠点は、設定を書くだけでも多少は Ruby の知識が要求されることです。 文字列だけいじっておけば設定は済むのようになっているので Ruby を知らない人間でも設定くらいできるはずですが、 素人はプログラムと聞くだけで機能停止するので、現実的ではありません。
また、このオブジェクト一個を受け取るやりかたを使うと 設定が一ヶ所に集中しないので、 ウェブから設定させるのは少々面倒かもしれません。
その他
他に考えられる手法としては、 アプリケーション側からオブジェクトを渡して値をセットさせる手法がありえます。 設定ファイルは次のように書いておいて、
config.data_path = '/var/tdiary'
config.cache_path = '/var/cache/tdiary'
config.secure = false
config.multi_user = false
config.lang = 'ja'
config.index = './'
config.update = 'update.rb'
config.style = 'tDiary'以下のようにロードします。
class Config
def Config.load(path)
config = new()
eval File.read(path), binding()
end
attr_accessor :data_path
attr_accessor :cache_path
attr_accessor :secure
attr_accessor :multi_user
attr_accessor :lang
attr_accessor :index
attr_accessor :update
attr_accessor :style
endまた、ハッシュを一つだけ渡すやりかたも比較的よく使われています。 例えば以下のような設定ファイル config を書いておいて、
module SomeApp
Config = {
:bind => '192.168.1.1',
:port => 1025
}
end以下のように load でロードします。
def load_config(path)
# $: から探さないようにするため、フルパスを指定すべき
load File.expand_path(path)
end
p SomeApp::Config[:port]この手法は QuickML や ftpup で使われています。 このやりかたも設定項目の変更には弱いので、 できるだけオブジェクトでラップしたほうがよいでしょう。
最後に、あまりに変態的なので誰もやらないと思いますが、 原理的にはローカル変数でパラメータを渡すことも不可能ではありません。 以下のような設定ファイルを用意して、
data_path = '/var/tdiary'
cache_path = '/var/cache/tdiary'
secure = false
multi_user = false
lang = 'ja'
index = './'
update = 'update.rb'
style = 'tDiary'次のように eval と Binding を駆使します。
def load_config(path)
src = File.read(path)
src.concat "\nbinding()"
eval(src)
end
b = load_config('config')
p eval('data_path', b)正直、自分で書いていながらどういう価値があるのかよくわかりません。
Tropy への応用
では、以上の話を Tropy に応用してみましょう。 手法としては、Tropy の現状に最も近い、 メソッドでオブジェクト一個を渡す方式を採用します。
まず sample.cgi は以下のようになります。
#!/usr/local/bin/ruby
load './config'
tropy_context().cgi_main設定ファイル config は以下のようになります。
$KCODE = 'SJIS'
$LOAD_PATH.unshift './lib'
require 'tropy'
def tropy_context
db = Tropy::Database.new("db.pstore", "shift_jis")
screen = Tropy::ScreenManager.new(
:baseurl => "http://www.example.com/tropy/sample.cgi",
:theme => "default",
:templatedir => "template")
Tropy::Application.new(db, screen)
endオリジナルからの変更点は以下の 4 点です。
- Tropy::Tropy クラスを Tropy::Application と改名
- Tropy::Application.new ですべての仕事をやるのをやめた
- Tropy::ScreenManager クラスを追加
- Tropy::Database.new に第二引数 encoding を追加
Tropy はもともとオブジェクトを渡すようになっていますし、 設定する項目もさほど多くないので、今回の変更は容易でした。
おわりに
いかがだったでしょうか。 今回は久しぶりにリフレクションがほとんど出てこない、 正統派添削をやってみました。 今回のポイントは以下の 7 点です。
- クラスを継承するときには三つのチェックポイントを確認しよう
- インターフェイスを考えるときは既存のクラスに見立てよう
- 使うクラスのメソッドをよく調べよう
- 一つのメソッドでは一つの操作だけを実装しよう
- オブジェクトの外から呼ばせたくないメソッドは private にしよう
- new に操作を詰め込むのはやめよう
- 引数を渡すためにインスタンス変数を使うのはやめよう
他にも具体的な話はいくつかしましたが、 汎用的に役立つのはこの 7 点でしょう。 みなさんも自分のクラスをデザインするときにこの 7 点を応用してみてください。
ちなみに、本当は FastCGI 対応とか PStore を捨てる話もやりたかったのですが、 分量と締め切りの都合からやむなくカットしました。 カットした分はいずれどこかで再録したいと思います。
最後に、添削前・添削後それぞれのソースコードを置いておきます。 見比べてみてください。
- 添削前: sample.cgi (オンラインで表示)
- 添削前: tropy.rb (オンラインで表示)
- 添削後: index.cgi (オンラインで表示)
- 添削後: config (オンラインで表示)
- 添削後: tropy.rb (オンラインで表示)
- CodeReview-0015.tar.gz (すべてまとめてダウンロード)
次回予告
例によって次回の予定は未定です。 添削してほしいプログラムをお持ちのかたは Subject に 「添削希望」と書いてるびま編集部にプログラムを送りつけてください。 ただし、添削するプログラムはオープンソースソフトウェアに限ります。
ではまた次回の添削でお会いしましょう。
著者について
青木峰郎(あおき・みねろう)
ふつうの文系プログラマ。本業は哲学らしい。 最新刊『‘ふつうの Haskell プログラミング’』はおかげさまで大好評発売中です。